2025년 11월 18일. 구글(Google)의 Gemini 3.0 발표는 단순한 대규모 언어 모델(LLM)의 세대교체를 넘어, 인공지능이 수동적인 정보 처리 도구에서 능동적인 행위자(Agent)로 진화하는 중대한 변곡점을 시사한다. 지난 수년간 생성형 AI(Generative AI)는 텍스트와 이미지를 생성하는 창작의 도구로 자리 잡았으나, 복잡한 현실 세계의 문제를 해결하거나 다단계의 논리적 추론을 수행하는 데에는 한계를 보여왔다. Gemini 3.0은 이러한 한계를 극복하기 위해 설계된 구글 딥마인드(Google DeepMind)의 야심 찬 프로젝트로, ‘추론(Reasoning)’과 ‘에이전트(Agent)’라는 두 가지 핵심 축을 중심으로 AI의 정의를 재정립하고 있다.
Gemini 3.0의 아키텍처 진화와 기술적 기반
Gemini 3.0은 이전 세대인 Gemini 1.0의 멀티모달 기초와 Gemini 2.0의 도구 사용 능력을 통합하고 확장한 결과물이다. 이 모델은 텍스트, 이미지, 오디오, 비디오, 코드 등 서로 다른 유형의 데이터를 별도의 변환 과정 없이 네이티브(Native)하게 이해하고 처리할 수 있는 진정한 의미의 멀티모달 아키텍처를 갖추고 있다.
– 네이티브 멀티모달리티(Native Multimodality)와 컨텍스트 처리
Gemini 3.0의 가장 큰 특징 중 하나는 100만 토큰(1 million tokens)에 달하는 방대한 컨텍스트 윈도우(Context Window)를 기본적으로 지원한다는 점이다. 이는 단순히 많은 양의 텍스트를 기억하는 것을 넘어, 수 시간 분량의 비디오, 수천 페이지의 문서, 거대한 코드베이스를 단일 컨텍스트 내에서 통합적으로 분석하고 추론할 수 있음을 의미한다. 기존 모델들이 외부 검색(RAG)이나 요약에 의존해야 했던 대규모 정보 처리 작업을 단일 추론 과정으로 처리함으로써 정보의 손실을 최소화하고 맥락의 연속성을 유지한다.
특히, Gemini 3.0은 비디오와 오디오 처리에 있어 비약적인 발전을 이루었다. ‘Video-MMMU’ 벤치마크에서 87.6%의 점수를 기록하며 경쟁 모델들을 압도했는데, 이는 영상 내의 시각적 정보와 청각적 정보를 결합하여 장면의 인과관계를 이해하고, 특정 사건이 발생한 시점을 정확히 찾아내거나 복잡한 행동을 분석하는 능력이 인간 전문가 수준에 도달했음을 시사한다.
– 추론(Reasoning) 중심의 설계: 시스템 1에서 시스템 2로
Gemini 3.0 아키텍처의 핵심은 ‘추론’ 능력의 강화이다. 인간의 인지 과정에 비유하자면, 기존의 LLM이 직관적이고 빠른 응답을 생성하는 ‘시스템 1(System 1)’ 사고에 치중했다면, Gemini 3.0은 논리적이고 분석적인 단계를 거치는 ‘시스템 2(System 2)’ 사고를 구현하는 데 주력했다. 이는 모델이 복잡한 질문에 직면했을 때, 즉시 답변을 내놓는 대신 내부적으로 사고하는 과정(Chain of Thought)을 거치도록 설계되었음을 의미한다.
이러한 설계 철학은 모델이 사용자의 의도(Intent)와 미묘한 뉘앙스(Nuance)를 파악하는 데 결정적인 역할을 한다. 사용자가 불완전하거나 모호한 프롬프트를 입력하더라도, Gemini 3.0은 문맥을 통해 숨겨진 의도를 유추하고 최적의 결과를 도출할 수 있다. 구글은 이를 통해 사용자가 복잡한 프롬프트 엔지니어링(Prompt Engineering) 없이도 AI를 효과적으로 활용할 수 있는 ‘Less Prompting’ 시대를 예고하고 있다.
모델 라인업 및 핵심 기능 심층 분석
Gemini 3.0은 범용성과 특수 목적을 아우르는 모델 패밀리로 구성되어 있으며, 각 모델은 특정 사용 사례에 최적화된 성능을 제공한다.
– Gemini 3 Pro: 차세대 범용 지능의 표준
Gemini 3 Pro는 균형 잡힌 성능과 효율성을 제공하는 미드레인지급 이상의 모델로, 광범위한 자연어 처리, 코딩, 멀티모달 작업에 최적화되어 있다. 특히, 이 모델은 ‘Google AI Studio’와 ‘Vertex AI’를 통해 개발자와 기업에 제공되며, 실시간성(Latency)과 추론 깊이 사이의 최적점을 찾아냈다.
Gemini 3 Pro는 Gemini CLI와의 통합을 통해 개발자 경험을 혁신한다. 터미널 환경에서 직접 구동되는 Gemini 3 Pro는 복잡한 쉘 명령어를 생성하거나, 코드 리팩토링을 제안하고, 에러 로그를 분석하여 해결책을 제시하는 등 개발자의 워크플로우에 깊숙이 침투한다. 특히, 자연어 명령을 통해 복잡한 엔지니어링 작업을 자동화하는 ‘에이전틱 코딩(Agentic Coding)’ 기능은 개발 생산성을 획기적으로 향상시킬 잠재력을 지니고 있다.
– Gemini 3 Deep Think: 심층 추론을 위한 전문화된 모드
Gemini 3 Deep Think는 Gemini 3.0 발표의 하이라이트이자, 가장 진보된 추론 능력을 보여주는 모델이다. 이 모델은 OpenAI의 o1 또는 o3 시리즈와 경쟁하는 포지셔닝을 가지며, 수학, 과학, 고난도 코딩과 같이 깊이 있는 사고가 필요한 영역에서 탁월한 성능을 발휘한다.
작동 메커니즘 (Thinking Tokens): Deep Think 모드는 답변을 생성하기 전에 ‘생각하는 토큰(Thinking Tokens)’을 생성하여 문제를 분해하고, 논리적 단계를 검증하며, 다양한 해결 경로를 탐색한다. 개발자는 API를 통해 thinkingLevel (Low/High)을 조절하거나 thinkingBudget을 설정하여 모델의 사고 깊이를 제어할 수 있다. 이는 비용과 응답 시간, 그리고 답변의 품질 사이에서 유연한 선택권을 제공한다.
성능 벤치마크: 초기 테스트 결과, Gemini 3 Deep Think는 박사급 지식을 요하는 GPQA Diamond 벤치마크에서 **93.8%**라는 경이적인 정답률을 기록했다. 또한, 매우 높은 난이도로 알려진 Humanity’s Last Exam에서도 도구 사용 없이 **41.0%**를 기록하며, 기존 모델들이 해결하지 못했던 영역에서의 가능성을 입증했다.
배포 전략: 현재 Deep Think 모드는 안전성 테스트를 거쳐 ‘Google AI Ultra’ 구독자와 일부 개발자들에게 순차적으로 공개될 예정이다. 이는 모델의 강력한 추론 능력이 오용될 가능성을 사전에 차단하고, 충분한 검증을 거치기 위한 신중한 접근으로 해석된다.
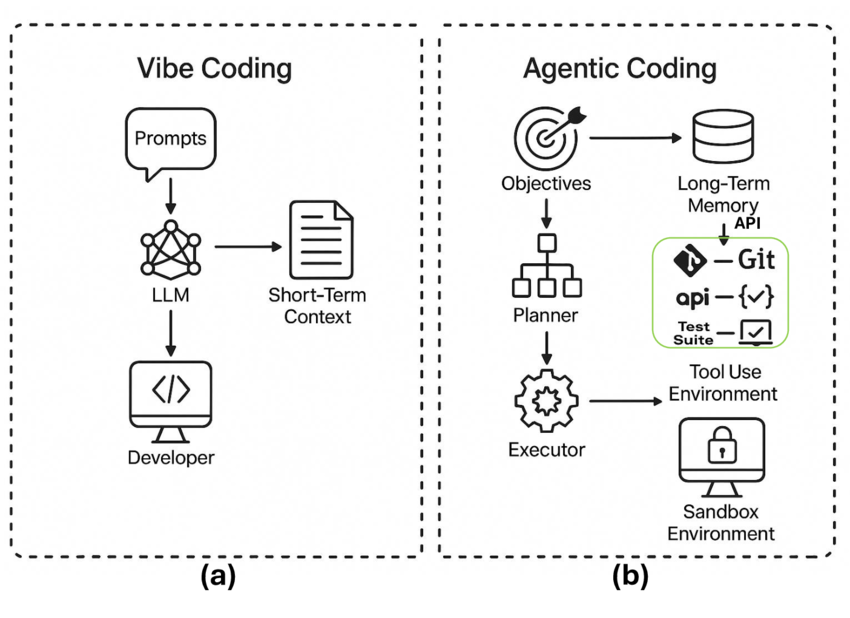
Vibe Coding: 소프트웨어 개발의 새로운 패러다임
Gemini 3.0과 함께 구글이 제시한 **’Vibe Coding’**은 코딩의 민주화를 넘어, 개발의 본질을 재정의하는 개념이다. 이는 엄격한 구문(Syntax)과 로직 작성에 집중하던 전통적인 코딩 방식에서 벗어나, 자연어와 직관(Vibe)을 통해 소프트웨어를 ‘지휘’하는 방식으로의 전환을 의미한다.
– Vibe Coding의 철학 및 워크플로우
Vibe Coding의 핵심 철학은 “인간은 의도를 정의하고, AI는 구현을 담당한다”는 것이다. 개발자가 자연어로 원하는 기능, 디자인 스타일, 작동 방식을 설명하면, Gemini 3.0은 이를 해석하여 실행 가능한 코드를 생성한다.
반복적 정제 과정 (Iterative Refinement Loop):
목표 설정 (Describe): “모던한 디자인의 할 일 관리 앱을 만들어줘”와 같은 고수준의 프롬프트로 시작한다.
생성 (Generate): AI가 초기 코드와 프로젝트 구조를 생성한다.
실행 및 관찰 (Execute & Observe): 생성된 앱을 즉시 실행하여 결과를 확인한다.
피드백 (Refine): “버튼 색상을 파란색으로 바꾸고, 완료된 항목은 줄을 그어줘”와 같이 대화형으로 수정 사항을 지시한다.
이러한 과정은 Google AI Studio의 새로운 ‘Build’ 모드를 통해 구현된다. 사용자는 별도의 개발 환경 설정 없이 웹 브라우저 상에서 코드를 생성하고, 미리보기를 확인하며, Google Cloud Run을 통해 즉시 배포까지 완료할 수 있다.
– Vibe Coding의 기술적 구현과 도구
Vibe Coding은 단순한 코드 자동 완성을 넘어선다. Gemini Code Assist와 같은 도구는 IDE 내에서 개발자의 의도를 파악하여 전체 함수를 작성하거나, 테스트 코드를 자동으로 생성하고, 복잡한 리팩토링을 수행한다. 또한, 사용자가 손으로 그린 UI 스케치나 에러가 발생한 화면의 스크린샷을 업로드하면, Gemini 3.0의 멀티모달 시각 능력을 활용하여 이를 코드로 변환하거나 버그의 원인을 분석해준다.
이는 개발 진입 장벽을 획기적으로 낮출 뿐만 아니라, 숙련된 개발자들에게도 반복적인 코딩 작업에서 해방되어 아키텍처 설계나 비즈니스 로직과 같은 고부가가치 업무에 집중할 수 있는 기회를 제공한다. 실제로 초기 사용자들은 Vibe Coding을 통해 수일이 소요되던 프로토타이핑 작업을 몇 분 만에 완료하는 사례를 보고하고 있다.
에이전틱 AI 생태계: Google Antigravity와 Gemini Agent
Gemini 3.0의 궁극적인 목표는 자율적으로 행동하는 에이전트(Agent)를 구축하는 것이다. 구글은 이를 위해 Google Antigravity라는 새로운 플랫폼을 선보였다.
– Google Antigravity: 에이전트 개발의 중추
Google Antigravity는 개발자가 Gemini 3.0의 추론 능력과 도구 사용 능력을 활용하여 복잡한 에이전트 워크플로우를 설계하고 배포할 수 있는 통합 환경이다.
자율적 도구 사용 (Autonomous Tool Use): Antigravity 기반의 에이전트는 단순히 텍스트를 생성하는 것을 넘어, 외부 API를 호출하고, 데이터베이스를 조회하며, 웹 브라우징을 수행하여 실질적인 작업을 완료한다. 예를 들어, “다음 주 도쿄 출장 일정을 잡아줘”라는 명령에 대해 항공권 검색, 호텔 예약, 캘린더 등록, 동료들에게 이메일 발송까지 스스로 수행할 수 있다.
엔터프라이즈 통합: Antigravity는 기업 환경에서의 사용을 염두에 두고 설계되었다. Vertex AI와의 연동을 통해 기업의 보안 정책을 준수하면서 사내 데이터를 활용하는 에이전트를 구축할 수 있으며, 이는 고객 서비스 자동화, 내부 문서 검색, 데이터 분석 등 다양한 업무 영역에 적용될 수 있다.
– 소비자용 Gemini Agent의 진화
일반 사용자를 위한 Gemini 앱 또한 Gemini 3.0 기반의 에이전트 기능을 대폭 강화했다. Gemini Agent는 사용자의 이메일 보관함(Inbox)을 정리하거나, 복잡한 여행 계획을 수립하고, 쇼핑 리스트를 관리하는 등 개인 비서로서의 역할을 수행한다. 특히, 구글의 방대한 서비스(Gmail, Maps, Calendar, YouTube 등)와 긴밀하게 통합되어 있어, 사용자 데이터에 기반한 개인화된 서비스를 제공한다는 점에서 타 플랫폼 대비 강력한 경쟁 우위를 점한다.
경쟁 모델 비교 분석: Gemini 3 vs. GPT-5.1 vs. Claude 3.7
2025년 하반기는 AI 기술 경쟁이 정점에 달한 시기이다. 구글의 Gemini 3, OpenAI의 GPT-5.1, Anthropic의 Claude 3.7이 거의 동시에 시장에 출시되면서 각 모델의 장단점과 특징이 뚜렷하게 드러나고 있다.
– 벤치마크 성능 비교 (Technical Benchmarks)
다음은 주요 벤치마크 결과를 바탕으로 세 모델의 성능을 비교한 표이다.
평가 항목 (Benchmark)
Gemini 3.0 (Deep Think / Pro)
GPT-5.1 (Thinking / Instant)
Claude 3.7 Sonnet (Extended Thinking)
분석 및 시사점
GPQA Diamond (과학적 지식)
93.8% (Deep Think)
88.1%
84.8%
전문 지식과 심층 추론에서 Gemini 3 Deep Think가 가장 앞서 있음을 보여줌.
Humanity’s Last Exam (고난도 추론)
41.0% (Deep Think)
26.5%
13.7%
기존 벤치마크로 측정하기 어려운 초고난도 문제 해결 능력에서 Gemini 3가 압도적 우위를 점함.
SWE-bench Verified (코딩)
54.9% (Deep Think)
–
70.3%
순수 텍스트 기반 코딩 문제 해결 능력은 여전히 Claude 3.7이 강세를 보임. 단, Gemini는 멀티모달 코딩에 강점.
MathArena / MATH 500 (수학)
23.4% (Apex High Score)
–
96.2% (MATH 500)
수학적 문제 해결에서는 Claude 3.7과 OpenAI 모델들이 강력한 성능을 보임.
MMMU-Pro (멀티모달)
81.0%
–
75% (MMMU)
이미지, 비디오, 텍스트가 결합된 멀티모달 추론 능력은 Gemini 3가 독보적임.
LMArena Elo Rating
1501
–
–
사용자 선호도를 반영하는 Elo 점수에서 Gemini 3 Pro가 역대 최고점을 기록하며 범용성을 입증.
– 모델별 특성 및 포지셔닝
Gemini 3.0:‘멀티모달 추론의 제왕’. 텍스트뿐만 아니라 비디오, 코드, 이미지를 아우르는 복합적인 문제 해결에 가장 강력하다. 구글 생태계와의 통합, 100만 토큰의 컨텍스트 윈도우가 강점이다. Deep Think 모드는 과학 연구나 복잡한 분석 업무에 최적화되어 있다.
GPT-5.1:‘대화형 AI의 완성형’. ‘Instant’ 모드를 통해 더 따뜻하고(Warmer tone) 인간적인 대화 스타일을 제공하며, 사용자 경험(UX) 측면에서 강점을 보인다. ‘Thinking’ 모드를 통해 추론 능력을 보완했으나, 순수 추론 깊이에서는 Gemini 3 Deep Think에 다소 밀리는 양상이다.
Claude 3.7:‘코딩 및 투명한 사고’. 개발자들 사이에서 가장 신뢰받는 코딩 모델(Code Assistant)로 자리 잡았다. ‘Extended Thinking’ 모드를 통해 사고 과정을 투명하게 보여주는 것이 특징이며, 엔지니어링 작업에서의 정밀도가 높다.
최근 출시된, Gemini 3.0은 구글이 추구하는 범용 인공지능(AGI)으로 가는 여정에서 가장 강력하고 실질적인 도약이다. 기업과 개인은 이 새로운 도구를 어떻게 업무 프로세스에 통합하고, 새로운 비즈니스 기회를 포착할 것인지에 대한 전략적 고민을 시작해야 할 시점이다. Gemini 3.0이 가져올 변화는 이제 막 시작되었으며, 그 파급력은 우리가 상상하는 것 이상일 것이다.
오랫동안 아이폰 사용자들의 숙원이었던 교통카드 기능이 마침내 실현되었습니다. 2025년 7월부터 한국에서도 Apple Wallet(지갑) 앱에 티머니 교통카드를 추가하여, 실물 카드 없이 아이폰 또는 애플 워치만으로 지하철, 버스 등 대중교통을 이용할 수 있게 되었습니다. 서울을 비롯한 대한민국 전역의 지하철 및 버스 대부분에서 아이폰을 태그하여 승차할 수 있으며, 편의점 등 티머니 가맹점에서도 결제 수단으로 사용할 수 있습니다
아이폰과 애플 워치에 추가된 Apple Pay 티머니 카드 화면. iPhone이나 Watch만 가볍게 태그하면 전국 대중교통을 이용할 수 있다.
애플페이 티머니 개요 및 장점
오랫동안 아이폰 사용자들의 숙원이었던 교통카드 기능이 마침내 실현되었습니다. 2025년 7월부터 한국에서도 Apple Wallet(지갑) 앱에 티머니 교통카드를 추가하여, 실물 카드 없이 아이폰 또는 애플 워치만으로 지하철, 버스 등 대중교통을 이용할 수 있게 되었습니다. 서울을 비롯한 대한민국 전역의 지하철 및 버스 대부분에서 아이폰을 태그하여 승차할 수 있으며, 편의점 등 티머니 가맹점에서도 결제 수단으로 사용할 수 있습니다
애플페이 티머니는 **익스프레스 모드(Express Mode)**를 지원하여, 아이폰을 잠금 해제하거나 앱을 실행할 필요 없이 단말기에 가까이 대기만 하면 자동으로 결제가 이루어집니다. 심지어 아이폰 배터리가 완전히 방전된 후에도 최대 5시간까지 교통카드 기능을 사용할 수 있는 전원 절약 모드도 지원됩니다. 잔액 확인 및 충전도 아이폰의 지갑 앱에서 바로 가능하고, 자동 충전 기능을 통해 잔액 부족 걱정 없이 이용할 수 있다는 편리함이 있습니다. 아래에서는 Apple Pay 기반 티머니 카드의 등록 방법부터 사용법, 충전 방법, 이용 가능 지역/교통수단, 그리고 실물 카드 대비 장단점까지 차례로 알아보겠습니다.
애플페이 티머니 등록 절차
아이폰에서 티머니 교통카드를 사용하려면, 우선 Apple 지갑 앱에 티머니 카드를 추가해야 합니다. 절차는 다음과 같습니다:
지원 기기 및 iOS 버전 확인: 아이폰 XS/XR 이후 모델이고 iOS 17.2 이상(애플 워치는 Series 6 이상에 watchOS 10.2 이상)이어야 합니다. 구형 기기는 지원되지 않으니 유의하세요. 또한 선불형 티머니 카드만 추가 가능하며(후불 교통카드는 미지원), 아이폰과 애플 워치에 각각 별도로 카드 발급이 필요합니다.
지갑 앱에서 카드 추가: 아이폰의 Wallet (지갑) 앱을 열고 “+” (추가) 버튼을 탭합니다. 메뉴에서 **“교통 카드”**를 선택하고 **“Tmoney”**를 고르면, 화면 안내에 따라 새로운 티머니 교통카드를 발급할 수 있습니다. 이때 최소 충전 금액을 설정하라는 안내가 나오며, 초기 등록을 위해 일정 금액을 충전해야 합니다. 원하는 금액을 애플페이를 통해 결제하면 티머니 카드가 지갑에 추가됩니다. 발급과 충전에 국내 발급 신용/체크카드 (애플페이에 등록된 카드) 가 필요합니다. 현재(2025년 7월) 애플페이에서 지원되는 국내 카드사가 제한적이므로, 현대카드 등 애플페이 등록 카드가 있어야 이 방법으로 충전까지 완료할 수 있습니다.
모바일 티머니 앱 이용 (대안): 만약 현대카드 등 애플페이 가능 카드가 없다면, 모바일 티머니 iOS 앱을 통해 우회할 수 있습니다. App Store에서 “모바일 티머니” 앱을 최신 버전으로 설치/업데이트한 뒤 실행하고, 앱 내에서 모바일 티머니 카드를 새로 발급합니다. 발급된 카드에 다른 신용/체크카드나 계좌이체 등으로 충전한 다음, 해당 티머니 카드를 아이폰 지갑에 추가하면 됩니다. 이렇게 하면 현대카드가 없어도 아이폰에 충전된 티머니 카드를 사용할 수 있습니다. 다만 이 방식은 별도의 앱 설치와 본인 인증 절차가 필요하며, 충전 수단에 따라 일부 수수료가 부과될 수 있습니다
Tip: 애플 워치에서도 티머니를 쓰고 싶다면, 아이폰에서 티머니 카드를 발급한 후 Watch 앱의 “지갑 및 Apple Pay” 설정으로 들어가 애플 워치에 티머니 카드 추가를 진행해야 합니다. 아이폰에 추가한 카드가 자동으로 워치에 동기화되는 것은 아니므로, 워치용으로 별도 발급·추가하세요
지갑 앱에서의 사용 방법
일단 지갑 앱에 티머니 교통카드를 추가했다면, 사용 방법은 기존 실물 티머니 카드와 거의 동일합니다. 아이폰이나 애플 워치로 지하철 개찰구 단말기나 버스 단말기에 가져다 대기만 하면 결제됩니다. 익스프레스 모드 덕분에 별도의 Face ID 인증이나 화면 켜기도 필요 없으며, 잠긴 화면 상태에서도 태그만으로 인식됩니다. 태그 시 진동/소리와 함께 화면 상단에 티머니 카드 이미지와 잔액 변동 등이 잠깐 표시되어, 성공적으로 결제되었는지 확인할 수 있습니다. 애플 워치 역시 화면을 켤 필요 없이 단말기에 가까이 대면 진동 피드백과 함께 승차가 완료됩니다.
잔액 확인 및 이용 내역: 아이폰의 지갑 앱에서 티머니 카드를 선택하면 현재 잔액이 표시됩니다. 카드를 아래로 스크롤하면 최근 거래 내역도 확인할 수 있어, 언제 어디서 얼마나 사용했는지 볼 수 있습니다
또한 티머니 카드 우측 상단의 “⦁⦁⦁” 버튼을 탭하면 카드 세부 설정 메뉴가 열리며, 여기서 자동 충전 설정이나 카드 삭제, 익스프레스 모드가 활성화 여부 등을 관리할 수 있습니다. 참고로 애플페이 티머니는 기본적으로 첫 추가 카드에 익스프레스 모드가 자동 활성화되며, 만약 티머니 카드를 여러 장 추가한 경우 하나만 Express로 설정되고 나머지는 수동 선택해야 사용 가능합니다.
오프라인 결제: 티머니 카드는 대중교통 외에도 편의점, 택시 등 티머니 가맹점에서 소액결제 수단으로 사용할 수 있습니다. 결제 시 “티머니로 결제할게요”라고 말한 뒤 아이폰을 리더기에 태그하면, 교통카드 잔액에서 금액이 차감되어 결제됩니다. 이때도 대체로 익스프레스 모드로 인식되지만, 일부 단말기에서는 인식이 다소 지연되거나 실패할 수 있으니, 화면에 표시되는 완료 여부를 확인하는 것이 좋습니다.
저전력 모드: 아이폰 배터리가 부족한 경우에도 최대 5시간까지는 교통카드 기능이 유지됩니다. 배터리가 0%로 꺼진 상태에서 교통카드를 태그하면, 전원 절약 모드로 잔여 시간 동안 결제가 가능하므로 긴급한 상황에서 유용합니다. 다만 5시간이 지나 완전히 방전된 경우나 기기를 분실한 경우를 대비해 예비용 실물 카드를 소지하거나, 애플 워치를 함께 활용하는 것도 안전한 방법입니다.
충전 및 자동 충전 방법 (지원 결제 수단)
애플페이 티머니 카드는 충전식(선불) 교통카드이므로, 잔액이 충분해야 사용할 수 있습니다. 충전하는 방법은 여러 가지가 있으며, 지원되는 결제 수단에도 차이가 있습니다. 주요 충전 방법과 특징은 아래 표와 같습니다:
충전 방법
특징 및 결제 수단
지갑 앱 직접 충전
애플 Wallet 앱에서 티머니 카드 선택 후 “충전” 메뉴 사용. 애플페이에 등록된 국내 발급 신용/체크카드로 결제되어 즉시 충전됨. 수수료 없이 즉시 충전 가능하지만, 현재 국내에서 애플페이를 지원하는 카드사(예: 현대카드)에 한해 이용 가능.
모바일 티머니 앱 충전
티머니 공식 앱에서 충전 금액 선택 후 다양한 결제 수단 사용 가능. 애플페이에 등록되지 않은 다른 신용/체크카드, 계좌이체, 간편결제 등을 통해 충전할 수 있음. 일부 결제 수단은 소액결제 수수료 (~2%)가 붙을 수 있으며, 충전 후 해당 금액이 지갑의 티머니 카드에 반영된다.
오프라인 충전
편의점(CU, GS25 등)이나 지하철 자동충전기 에서 현금으로 충전. 아이폰의 티머니 카드를 리더기에 태그하여 실물 카드처럼 충전할 수 있다. 편의점은 점포마다 지원 여부가 다를 수 있고, 지하철 무인 충전기는 수수료 없이 이용 가능.
충전한 금액은 즉시 티머니 카드 잔액에 반영되며, 충전 최대 한도는 50만 원입니다 (실물 카드와 동일). Apple 지갑에서의 자동 충전 기능도 세계 최초로 도입되었는데, 이를 활용하면 잔액이 일정 금액 이하로 내려갈 때 미리 설정한 금액만큼 자동으로 충전됩니다. 지갑 앱의 카드 설정에서 **“자동 충전”**을 켜고 *기준 잔액 (예: 5,000원 이하)*과 *충전 금액 (최소 1만 원~)*을 지정하면, 이후부터는 잔액이 부족해도 자동으로 카드에 금액이 추가됩니다. 예를 들어 잔액 7,000원 이하로 떨어지면 20,000원을 자동충전하도록 설정해 두면 출퇴근 시 잔액 부족으로 곤란을 겪을 일이 사라집니다. 자동충전 시 결제되는 카드 역시 애플페이에 등록된 국내 신용카드로 한정되며, 현재로선 현대카드로 설정하는 경우가 많습니다. 자동 충전 설정/변경은 지갑 앱이나 티머니 앱 양쪽에서 모두 가능합니다.
2025년 7월 현재 애플페이 국내 서비스는 현대카드 단독으로 제공되고 있습니다. 지갑 앱에서 티머니를 충전하거나 자동충전을 이용하려면 현대카드처럼 애플페이에 등록된 국내 카드가 반드시 필요합니다. 현대카드가 없는 경우 앞서 언급한 티머니 앱 충전 또는 오프라인 충전 방식을 이용해야 합니다. 추후 신한카드, KB국민카드 등 다른 카드사의 애플페이 지원이 확대되면 지갑 앱 충전도 더 자유로워질 것으로 기대됩니다.
티머니 사용 가능 지역 및 교통수단
애플페이 티머니 카드는 기존 실물 티머니 교통카드와 동일한 범위에서 사용 가능합니다. 즉, 티머니로 결제할 수 있는 대부분의 교통수단에서는 아이폰 교통카드로도 이용이 가능하다는 뜻입니다. 수도권부터 지방까지 폭넓게 활용되지만, 일부 제한 사항도 있으므로 상세 내용을 정리하면 다음과 같습니다:
교통수단
티머니 사용 범위
지하철
서울·경기 수도권 전철 (1~9호선, 신분당선, 공항철도 등 모든 노선), 인천 지하철 1~2호선, 부산 1~4호선, 대구 1~3호선, 대전 1호선, 광주 1호선 등 전국 도시철도에서 사용 가능
시내버스
서울, 경기, 인천 등 수도권 전 지역의 시내버스 및 부산·대구·광주·대전·울산 등 광역시 버스, 그 외 강원·충청·경상·전라 대부분 지역의 시내·농어촌 버스까지 지원. 거의 전국 모든 도시에서 현금 대신 티머니로 버스 요금을 낼 수 있습니다.
택시
서울 및 수도권 전체, 6대 광역시, 그리고 대부분 기초지자체의 택시에서 티머니 결제 가능. 다만 일부 지방의 구형 단말기 택시는 티머니 결제를 지원하지 않을 수 있습니다.
시외버스
시외버스(광역버스) 요금 결제는 티머니 지원되지 않음. 고속도로를 이용하는 시외/고속버스의 터미널 현장 구매나 모바일 예매는 티머니로 불가능합니다.
고속버스
일부 고속버스 노선 한정으로 티머니 결제가 지원됨. (예: 금호고속, 동양고속, 중앙고속 등 일부 회사). 해당 고속버스 터미널 매표소에서 티머니로 승차권을 구매할 수 있습니다.
철도(KTX 등)
코레일에서 운행하는 KTX, ITX-새마을, 무궁화호 등 열차 승차권 구매에도 티머니 사용 가능. 자동발매기에서 티머니로 결제하여 승차권을 살 수 있습니다. (※ SRT는 별도 카드 필요)
요약하면, “티머니” 마크가 붙어 있는 거의 모든 교통수단에서 아이폰 티머니도 사용할 수 있다고 보면 됩니다. 실제로 기자 실험에 따르면, 아이폰에 추가한 티머니 카드로 서울 시내버스를 승차한 결과 1500원 요금이 정상 차감되며 실물 카드와 동일하게 동작했습니다. 단, 일부 시외버스와 일부 지역의 택시를 제외하고는 문제없이 이용 가능하나, 혹시 모를 단말기 미지원에 대비해 승차 전 티머니 결제여부를 미리 확인해보는 것이 좋습니다. 현재는 청소년 우대용 티머니나 기후동행카드/K패스 등 특수 할인 교통카드는 지원되지 않으므로(등록 불가), 해당 할인 혜택을 받으려면 아직 실물 카드를 이용해야 합니다.
실물 카드 대비 디지털 티머니의 장단점
스마트폰 속으로 들어온 디지털 티머니는 여러모로 편리하지만, 기존 실물 티머니 카드와 비교했을 때 장점과 단점이 있습니다. 이를 정리하면 다음과 같습니다:
디지털 티머니의 주요 장점
휴대 편의성: 지갑이나 카드 케이스를 들고 다닐 필요 없이 항상 소지하는 아이폰만으로 교통카드를 이용할 수 있습니다. 실물 카드 분실 위험도 사라집니다. 또한 아이폰과 애플 워치를 연동하면 손목만으로도 결제되는 등 일상 이동이 한층 간편해집니다.
**손쉬운 **충전 및 관리: 아이폰에서 언제든지 잔액 확인과 충전을 할 수 있어 편의점이나 역무기기 앞에서 번거롭게 충전할 필요가 없습니다. 자동 충전을 켜두면 잔액이 부족할 틈 없이 늘 일정 금액이 유지되어 안심입니다. 이 모든 충전 과정에 수수료가 없고(애플페이 충전 시) 매우 즉각적으로 처리가 됩니다.
보안 및 분실 대처: 애플페이 티머니는 Secure Element 칩을 통해 카드 정보를 안전하게 저장하고, 개인의 이용 내역을 애플이나 티머니가 추적할 수 없습니다. 기기를 분실하였을 경우 나의 찾기(Find My) 앱을 통해 원격으로 아이폰을 분실 모드로 전환하거나 티머니 카드를 즉시 사용 중지할 수 있어, 실물 카드를 잃어버렸을 때보다 보안 대응이 용이합니다.
빠른 태그 인식: 실제 사용 후기에 따르면 아이폰의 티머니 인식 속도는 매우 빨라 지하철 개찰구나 버스 단말기에서 실물 카드와 동일하게 즉시 인식됩니다. 특히 최신 교통 단말기와의 호환성이 좋아 쾌적하게 이용할 수 있습니다. (※ 다만 일부 구형 단말기는 인식이 살짝 지연될 수 있다고 보고됨)
추가 기능: 모바일 티머니 앱과 연동하여 티머니 마일리지 적립이나, 어린이/청소년 할인 설정 같은 부가 기능을 활용할 수 있습니다. 예를 들어 모바일 티머니 앱에서 해당 연령으로 등록하면 디지털 티머니 카드에도 청소년/어린이 교통할인 요금이 적용됩니다. (실물 할인카드는 별도 발급 절차가 필요한 반면, 모바일에서는 비교적 간편하게 설정 가능.)
디지털 티머니의 단점 및 유의사항
초기 설정 및 조건: 애플페이 지원 아이폰 (iPhone XS, XR 이후 모델) 이면서 iOS 17.4 이상이 설치되 있어있어야 하고, 국내 발급 카드가 애플페이에 등록되어 있어야 티머니 충전이 가능합니다. 특히 외국인 관광객의 경우 국내 신용카드가 없으면 아이폰에 티머니를 충전할 방법이 없어 사실상 사용이 불가능합니다. (일본의 Suica처럼 해외 카드로 바로 충전되지 않는 점이 아쉬운 부분입니다.) 현재 티머니 측에서도 외국인 관광객도 사용할 수 있는 방안을 검토 중이라고 하나, 아직까지는 한국 거주자 위주의 서비스임을 참고해야 합니다.
특수 할인/후불 기능 미지원: 앞서 언급했듯 후불형 티머니 카드 (신용카드 연계 교통결제)나 정기권/KPass/기후동행카드 등의 특수 기능은 디지털 티머니에서 지원되지 않습니다. 따라서 해당 할인 혜택을 받기 위해서는 실물 카드(또는 별도 앱)을 그대로 사용해야 합니다. 또한 현재 일부 티머니 선불카드의 잔액 이전도 직접적으로 할 수 없어, 기존 카드 잔액을 모바일로 옮기려면 번거로운 환불 절차나 마일리지 전환을 거쳐야 하는 불편도 있습니다.
기기별 개별 카드: 아이폰과 애플 워치를 둘 다 사용하는 경우 각 기기에 별도의 티머니 카드를 발급해야 합니다. 하나의 교통카드를 두 기기가 공유하지 못하므로, 두 장의 카드에 잔액을 각각 관리해야 합니다. 예를 들어 아이폰과 워치에 각각 5천 원씩 충전되어 있다면 한쪽을 다 쓰더라도 다른 쪽 잔액을 합쳐 쓸 수는 없습니다. 이 부분은 다소 비효율적일 수 있는데, 추후 아이클라우드 연동 등을 통한 개선이 기대됩니다.
기타 사항: 디지털 티머니는 초기 발급 시 최소 충전금액 부담(보통 1만원 내외 권장) 정도가 있으며, 실물 카드(통상 2,500원 구매) 대비 카드 발급 자체 비용은 없으나 충전 자금은 선불로 잡아두어야 합니다. 또한 아주 드물게 티머니 결제가 지원되지 않는 터미널이나 오류 상황이 있을 수 있으므로, 중요한 출퇴근시에 대비해 잔액 부족 알림을 켜두거나(자동충전 활용) 예비 수단을 준비하는 것이 좋습니다.
애플페이 도입은 아이폰 사용자들에게 큰 편의를 가져다주었습니다. 아직 몇 가지 제약 사항이 남아있지만, 향후 더 많은 카드사의 애플페이 참여와 외국인 이용 지원, 후불 기능 등이 확충 된다면 더욱 완성도 높은 서비스가 될 것으로 보입니다. 지금까지 실물 교통카드를 들고 다녔던 아이폰 사용자라면, 빠르고 편리한 애플페이 교통카드 기능을 꼭 사용해보시기 바랍니다.
한국과 일본은 4차 산업혁명의 핵심 기술인 인공지능(AI)과 정보기술(IT)을 헬스케어와 제조 분야에 적극 활용하여 산업 혁신을 추구하고 있다. 두 나라 모두 정부의 투자 정책, 기술 인프라 발전, 민간 기업의 참여를 통해 시장을 성장시키고 있지만, 접근 방식과 속도에서 차이가 나타난다. 본 보고서에서는 헬스케어 산업과 제조 산업에서 한국과 일본의 AI/IT 활용 현황, 정부 전략, 시장 규모와 성장률, 기술 사례를 비교해 본다.
헬스케어 산업의 AI/IT 활용 현황 비교
한국의 헬스케어 AI 활용과 투자 동향
한국의 헬스케어 산업은 AI와 바이오기술의 융합을 통해 디지털 헬스케어 혁신을 가속화하고 있다. 의료영상 판독 AI와 같은 진단 보조 솔루션이 병원에 도입되어 의료진 부족 문제와 만성질환 관리 등에 대응하고 있다. 한국 AI 헬스케어 시장 규모는 2023년 약 3억7천만 달러로 추산되며, **연평균 50.8%**의 폭발적 성장률로 2030년에는 66억7천만 달러(약 9조원)에 이를 전망이다. 이는 글로벌 평균 성장률(41.8%)과 아시아 평균(47.9%)을 상회하는 수치로, 루닛(Lunit), 뷰노(VUNO), 딥바이오 등 국내 의료 AI 선도기업들의 활약이 뒷받침하고 있다. 정부도 의료 AI R&D에 막대한 투자를 하고 있다. 최근 5년간 범정부적으로 의료 AI 분야에 2.2조원 규모의 연구개발 예산을 투입하며 매년 33%씩 증가시켰고, 2024년 보건의료 연구개발 예산 2조1천억 원 중 약 2,302억 원(10.9%)을 데이터·AI 의료 예산으로 편성하는 등 지속 지원 중이다. 이러한 지원 하에 국내에서는 AI 정밀의료 플랫폼, 환자 데이터 분석, 신약개발 AI 등 다양한 활용 사례가 나타나고 있다. 다만 원격의료와 같은 일부 분야는 규제 이슈로 도입이 더딘 측면이 있으나, 정부의 디지털 헬스 규제 샌드박스 등을 통해 점진적으로 해결하고 있다.
일본의 헬스케어 AI 활용과 투자 동향
일본 역시 고령화로 인한 의료비 증가와 의료인력 부족 문제를 해결하기 위해 헬스케어의 디지털 전환(DX)을 강력히 추진하고 있다. 일본 정부는 2030년까지 의료 DX 완성을 목표로 병원 간 데이터 공유, 원격의료 인프라, AI 진단 도구 도입을 촉진하는 종합 계획을 진행 중이다. 특히 2022년부터는 의료 AI 활용에 대한 보험수가 가산 제도를 도입하여, 일정 요건을 갖춘 의료기관이 CT/MRI 등의 판독에 AI 소프트웨어를 활용하면 추가 수가를 인정하고 있다. 이러한 정책으로 병원 현장에서 AI 도입을 유인하고, 민간 기업의 의료 AI 개발을 활성화하고 있다. 일본 AI 의료기기 시장은 이미 상당한 규모를 형성하고 있는데, 2022년 약 1,250억 엔(약 1조1천억원)에서 2027년에는 5,000억 엔(약 4조6천억원) 규모로 성장할 전망이다. 연평균 성장률은 약 **22.6%**로 예상되나, 한국에 비해서는 기저 규모가 크고 성장세는 완만한 편이다. 일본 경제산업성은 **「의료기기 산업 비전 2024」**를 수립하여 AI와 센서 기술을 접목한 첨단 의료기기의 고부가가치화를 추진하고 있으며, 스마트 병원 실증 사업 등을 통해 기술 인프라를 정비하고 있다. 민간 부문에서는 후지필름, 올림푸스 등 전통 의료기업이 AI 진단 솔루션을 개발하고, 소프트뱅크와 같은 ICT 기업도 헬스케어 스타트업에 투자하며 시장 참여를 확대하고 있다.
헬스케어 분야 한일 비교 요약
두 국가의 의료 분야 AI 활용 현황을 표로 비교하면 다음과 같다:
구분
한국
일본
AI 헬스케어 시장규모
2023년 약 3.7억 달러 → 2030년 66.7억 달러 전망 (연평균 +50.8%)
2022년 약 1,250억 엔 → 2027년 5,000억 엔 전망 (연평균 +22.6%)
정부 정책
의료AI R&D에 5년간 2.2조원 투자, 보건의료 데이터 투자 확대. 디지털헬스 규제완화 추진
2030 의료 DX 로드맵 추진, AI 진단 보험수가 신설, 의료기기 비전 2024 수립
기술 인프라
세계적 수준의 의료 데이터 인프라(의료영상 데이터센터 등) 구축 중. 일부 대형병원 AI 시범 도입
병원 정보시스템 표준화 낮았으나 데이터 플랫폼 실증 추진. 전국적 EHR 연결 및 클라우드 전환 노력
민간 기업 참여
루닛, 뷰노 등 스타트업이 영상판독 AI 글로벌 진출, 대기업 삼성 등도 디지털헬스 투자
후지필름(의료AI), NEC·히타치(헬스 IT) 등 전통강자와 AI 스타트업 공존; 소프트뱅크 등의 전략 투자 활발
특징 및 이슈
규제 샌드박스로 신기술 도입 촉진; 보험수가 등 수익모델은 미흡해 상용화 과제
고령화로 수요 급증; 정부 주도로 보험·인프라 정비. 국내 시장 폐쇄성 커 해외 기업 직접진출 어려움
한국은 높은 성장률과 스타트업 혁신이 강점이라면, 일본은 거대한 내수시장과 제도 지원이 뒷받침되는 양상이다. 한국 정부는 주로 R&D 투자와 인프라 구축에 집중하는 반면, 일본 정부는 **규제 개선과 수요 창출(보험수가 등)**에 초점을 맞추어 AI 활용을 유도하고 있다. 결과적으로 향후 양국 모두 의료AI 시장이 크게 확대될 것으로 보이며, 만성질환 관리, 영상 진단, 정밀의료 등에서 협력과 경쟁이 병존할 전망이다.
제조 산업의 AI 활용 (스마트팩토리·로보틱스) 현황 비교
한국 제조업의 스마트팩토리 추진과 AI 적용
한국 제조업에서는 스마트공장(Smart Factory)을 통한 디지털 전환이 지난 수년간 정책적 우선순위였다. 2014년부터 추진된 범정부 스마트팩토리 보급 사업을 통해 2022년까지 누적 3만 개의 스마트공장 구축 목표를 달성하며 제조현장 혁신의 토대를 마련했다. 2023년부터는 단순 자동화에서 나아가 지능형 자율제조로의 고도화를 추진 중이다. 정부는 2024년에도 2,180억원의 예산을 투입하여 중소기업 대상 스마트제조 혁신 지원사업을 이어가고, 신(新)디지털 제조혁신 전략 하에 제조 AI 솔루션 확산을 도모하고 있다. 이러한 지원으로 대기업뿐 아니라 중견·중소 제조업체들도 IoT, 클라우드, AI 분석 도구를 생산공정에 도입하고 있다. 예를 들어 포스코는 AI로 제강 공정의 품질을 관리하고, 현대자동차는 생산라인에 AI 비전검사 시스템을 적용하여 불량 검출률을 높이는 등 활용 사례가 다각화되고 있다. 한국은 제조 로봇 활용도에서도 세계 선두 수준인데, 제조업 종사자 1만 명당 로봇 1,000대 이상을 운영하여 글로벌 1위의 자동화 밀도를 보인다. 이는 일본(약 399대)이나 독일 등을 크게 앞서는 수치로, 생산현장의 설비 자동화 기반이 탄탄함을 보여준다. 또한 5G 통신 인프라와 클라우드 플랫폼의 발전으로 실시간 데이터 수집·분석이 용이해져, AI를 활용한 예지보전(예방정비)이나 공급망 최적화 등 고도 제조 AI 활용이 늘어나고 있다. 다만 중소기업의 경우 인력·자본 부족으로 여전히 기초 수준의 디지털화에 머무른 곳도 있어, 정부는 스마트제조 人재 양성과 솔루션 보급을 병행 추진하고 있다.
일본 제조업의 스마트팩토리 추진과 AI 적용
일본 제조업은 전통적으로 자동화와 로보틱스 분야에서 강점을 보여왔으며, 최근에는 AI와 IoT를 접목한 스마트팩토리로 진화하고 있다. 일본 정부는 「Society 5.0」 비전 아래 제조업의 AI 활용을 국가 경쟁력 강화의 핵심으로 인식하고 있다. 특히 인구감소와 노동력 부족 문제가 심화됨에 따라, 생산성 향상을 위한 중소기업 디지털화 지원책을 대대적으로 전개했다. 2020년 코로나19 위기 대응으로 편성한 사업재구축 보조금을 통해 제조업, 서비스업 등의 기업에 총 1조1,485억 엔 규모의 예산을 투입하여 공장 자동화·DX 프로젝트를 지원하였고, 2021년 이후에도 수차례 추가 모집을 실시하며 보조금 대상을 확대했다. 이로 인해 일본 중소 제조업체들의 스마트팩토리 도입이 활발해져, 팬데믹으로 지연됐던 프로젝트들이 재개되고 있다.
일본 국내 공장 디지털화 시장은 2021년도 발주액 기준 1조6,760억 엔(약 16조7천억원) 규모로 전년 대비 6.3% 성장했으며, 노후 설비 교체 수요와 인력난 대응 투자로 향후 꾸준한 증가세가 예상된다. 제조 현장에서는 예지보전, 품질검사 자동화, 작업자 지원 등 영역에서 AI 활용이 두드러지며, 대형 설비에 IoT 센서를 부착해 실시간 데이터를 수집하고 클라우드로 보내 AI가 분석·제어하는 데이터 기반 생산체계가 확산되고 있다. 예를 들어, Fanuc 등의 로봇기업은 딥러닝으로 로봇의 동작을 최적화하고, 도요타는 AI로 공급망 데이터를 분석하여 재고관리 효율을 높이는 등 사례가 보고된다.
일본은 산업용 로봇 생산국 1위답게 로봇 활용 인프라가 넓게 퍼져 있고, 이를 AI로 고도화하는 연구개발이 활발하다. 정부는 한편으로 로컬 5G 주파수를 기업에 할당하여 공장 내부 전용 5G망 구축을 장려하고, 표준화보다는 유연성에 중점을 두어 기업들이 자사에 맞는 스마트팩토리 솔루션을 채택하도록 유도하고 있다. 이러한 접근은 일본 제조업의 강점인 현장 카이젠(개선) 문화와 맞물려 생산성 향상에 기여하고 있지만, 중소기업의 디지털 인재 부족은 여전히 도전으로 남아 있다.
제조 분야 한일 비교 요약
제조 산업에서의 AI 및 스마트팩토리 추진을 비교하면 다음과 같다:
구분
한국
일본
스마트팩토리 보급 현황
2014~2022년 정부 주도로 3만 개 스마트공장 구축 완료. 이후 고도화 단계 진입
스마트공장 도입은 초기 단계였으나, 2020년 이후 보조금 확대로 중소기업까지 확산
제조 AI 시장규모
(별도 수치 공식 없음, 글로벌 제조AI 2019년 $81억→2032년 $6,951억 추정) 국내도 향후 10년간 높은 성장 전망
2021년 공장 DX 시장 1.676조 엔, 2025년 이후도 노후설비 교체·인력난으로 증가 예상
정부 지원 전략
중기부·산업부 협력 스마트제조혁신 정책, 매년 예산 지원 (’24년 2,180억 등). AI+5G 테스트베드 구축
세계 최고 수준 제조IT 인프라: 5G 공장 적용, 클라우드 MES 도입 증가, 높은 로봇 밀도
글로벌 최고 로봇 공급망 보유, 기업전용 5G(로컬5G) 도입 지원, 센서/IoT 기술 강점
민간 기업 동향
삼성전자, 현대차 등 대기업은 자체 스마트팩토리 플랫폼 운영; 중소기업은 정부 지원 통해 솔루션 도입
도요타, 혼다 등 제조 대기업은 AI로 생산최적화; 다수의 공장 자동화 전문기업(키엔스 등)과 SI기업이 중소기업 지원
주요 적용 사례
예지정비, AI 머신비전 검사, 생산스CHEDuling 최적화, 협동로봇 활용 등
AI 기반 설비오작동 예측, 에너지 효율 관리, 무인화 공정 (AGV, 로봇) 도입 등
과제
중소기업 인력·자금 격차, 데이터 표준화, 보안 이슈
디지털 인재 부족, 기업 간 데이터 표준 미흡, 경직된 기업문화의 변화 필요
종합하면, 한국은 정부의 강력한 드라이브로 빠르게 스마트공장 양적 확대에 성공했고 이제 질적 업그레이드에 초점을 맞추고 있다. 일본은 기존 제조강국의 기반 위에 AI와 DX를 도입하여 생산성 저하와 인력난에 대응하는 전략을 취하고 있다. 한국이 ICT 인프라와 속도 면에서 앞선다면, 일본은 정교한 제조기술과 현장혁신 노하우를 AI와 접목하는 데 강점을 보인다. 두 나라 모두 제조업의 AI 활용을 통해 비용 절감과 품질 향상을 이루고자 하며, 향후 자율공장, 사이버 물리 시스템 등 보다 진화된 스마트 제조로 나아갈 전망이다.
정부의 AI 산업 투자 및 육성 전략 비교
한국과 일본 정부 모두 AI를 국가 미래 경쟁력의 필수 요소로 인식하고 종합적인 육성 전략을 수립·시행하고 있다. 한국 정부는 2019년 발표한 「국가 AI 전략」에서 2030년까지 세계 3대 AI 강국 도약을 목표로 제시하고, 인프라, 인재, 활용 3대 분야에 걸쳐 민관 합계 2조원 이상의 투자를 추진했다. 이어 2020년부터 디지털 뉴딜 정책의 일환으로 AI 데이터 구축(일명 데이터 댐), AI 바우처 지원, 클라우드 및 5G 인프라 확대 등에 막대한 예산을 투입했다. 특히 AI 반도체와 AI 데이터센터 등 기반 기술 확보에도 집중하여, 2030년까지 총 4조원을 투입해 초거대 AI 연산 인프라를 구축하고 차세대 AI 칩 개발을 지원할 계획이다. 분야별로는 바이오·의료 AI, 제조 AI를 포함한 5대 선도 분야를 선정하여 R&D와 시범사업을 병행하고, 규제혁신을 통해 신기술 상용화를 촉진하고 있다. 한편 AI 인력 양성을 위해 전국에 AI 대학원(현재 10여 개)을 신설하고 실무 재교육 프로그램도 운영 중이다.
일본 정부는 「Society 5.0」 비전을 2016년 제시하며 AI를 저출산·고령화 등 사회문제 해결 수단으로 규정하였고, 2019년에는 범부처 협의체를 통해 **「AI 전략 2019」**를 수립하여 AI 인재육성, 산업화, 국제협력 방향을 제시하였다. 이후 코로나19를 겪으며 디지털화 지연을 반성하고 2022년에 **「AI 전략 2022」**를 개정, 국민 생활/안전 보장을 추가 목표로 설정하는 등 전략을 보강했다. 일본의 AI 산업 규모는 2027년에 약 1조1천억 엔 수준까지 성장할 것으로 전망되며, 정부는 이를 뒷받침하기 위해 반도체·디지털 산업 전략을 수립하여 데이터센터 확충, 첨단 반도체 투자 등을 병행하고 있다. 산업별 육성 측면에서, 경제산업성(METI)은 제조업, 모빌리티, 헬스케어 등 각 분야의 AI 활용을 지원하는 프로그램(NEDO 연구사업 등)을 운영하고 있으며, 총무성은 스마트시티와 연계한 지역 AI 서비스 모델을 추진 중이다. 또한 일본은 AI 인재 확보 전략으로 2020년대 들어 해외 고급 인력을 유치하기 위한 이민 완화, 영어로 진행되는 AI 전문 대학원 과정 신설 등도 도입하여 2020년 이후로는 AI 인재 순유입국으로 전환되었다는 평가가 있다. 전반적으로 일본 정부의 전략은 사회 문제 해결형 AI 구현에 초점을 맞춰 민관협력을 강화하고 있고, 국제적으로는 AI 거버넌스 논의에 적극 참여하여 윤리 기준 마련에도 힘쓰고 있다.
향후 10년간 기술 트렌드 및 시장 전망
향후 10년간 한일 양국 모두 헬스케어와 제조 분야에서 AI 도입이 본격적으로 확대되어 시장이 큰 폭으로 성장할 전망이다. 헬스케어 분야에서는 생성형 AI와 정밀의료 기술의 발전으로 개인별 맞춤 의료와 신약 개발 기간 단축이 현실화되고, 두 나라 모두 의료 데이터 표준화와 공유 플랫폼을 구축하여 AI 서비스의 기반을 강화할 것이다. 고령인구 증가로 원격 모니터링, AI 돌봄 로봇 수요가 증가하고, 일본은 이러한 디지털 헬스 기술을 통해 의료비 절감 효과를 추구할 것으로 보인다. 한국의 AI 헬스케어 시장은 앞서 언급한 대로 2030년에 9조원 규모로 성장할 것으로 예상되며, 일본도 같은 시기에 수조 엔대의 시장을 형성할 것이다. 제조 분야에서는 자율주행 로봇, 에지 AI(Edge AI)를 활용한 실시간 제어, 디지털 트윈을 통한 공장 시뮬레이션 등이 핵심 트렌드로 자리잡을 전망이다. 양국 제조업체들은 에너지 효율과 탄소중립 요구에도 대응해야 하므로 AI를 활용한 에너지 관리, 공정 최적화 기술이 필수적이 된다. 글로벌 컨설팅 기관들은 제조업 AI가 2030년대 초까지 폭발적으로 성장하여 전세계 시장규모 수천억 달러에 이를 것으로 보고 있으며, 한국과 일본 역시 이러한 세계 추세 속에서 스마트 제조 2.0 시대로의 전환을 가속화할 것이다. 일본은 노동력 감소를 AI·로봇으로 보완하는 데 주력하여 무인화 공장 비율이 높아질 가능성이 있고, 한국은 AI로 생산성을 극대화하여 제조 강국의 입지 강화를 노릴 것으로 보인다. 기술 인프라 측면에서는 클라우드-엣지 병행 아키텍처, 6G 통신(2030년경 상용화 예상) 등이 도입되어 AI 활용 범위가 더욱 넓어지고 지능화 수준이 심화될 것이다. 또한 AI 관련 보안 및 윤리 중요성이 커져, 안전하고 신뢰할 수 있는 AI(Safe & Trustworthy AI)를 구현하는 기술과 규제가 함께 발달할 전망이다.
결론
한국과 일본의 헬스케어 및 제조 산업에서의 IT와 AI 시장을 비교한 결과, 양국 모두 정부의 전략적 지원과 민간의 혁신 노력을 바탕으로 빠른 성장세를 보이고 있다. 한국은 세계 최고 수준의 디지털 인프라와 민첩한 스타트업 생태계를 발판으로 AI 활용을 확산시키고 있으며, 일본은 탄탄한 제조 기반과 거대한 내수시장을 바탕으로 AI를 사회문제 해결에 접목시키고 있다. 헬스케어 분야에서는 한국이 높은 성장률로 추격하고 일본이 제도 개선으로 활용도를 높이는 가운데, 의료AI 기술 개발과 실증 활용에서 상호 보완 및 경쟁 관계가 형성되고 있다. 제조 분야에서는 두 나라 모두 스마트팩토리 전환에 박차를 가하고 있으며, 한국은 ICT 융합 제조에, 일본은 로보틱스 결합 제조에 비교우위를 지닌 모습이다. 향후 10년간 AI 기술의 발전과 시장 확대는 양국 산업구조에 큰 변화를 가져올 것이며, 이에 대응한 인력 양성과 조직 혁신의 중요성이 더욱 부각될 것이다. 시니어 개발자를 비롯한 디지털 인재들은 양국에서 핵심 자원으로 대우받으며, 이들의 역량과 리더십이 산업 경쟁력의 성패를 결정짓는 열쇠가 될 것이다. 결국 한국과 일본 모두 **“사람 중심의 기술혁신”**을 이루는 것을 목표로, 협력과 선의의 경쟁을 통해 아시아 AI 시대를 견인할 것으로 기대된다.
Stable Diffusion을 사용하다 보면 자주 보이는 용어 중 하나가 바로 ‘가중치(weights)’입니다. 가중치란 간단히 말해 “특정 요소가 결과물에 얼마나 강력한 영향을 미치는지”를 나타내는 숫자라고 생각하면 쉽습니다.
가중치를 왜 사용하나요?
가중치는 AI가 이미지를 생성할 때 프롬프트 내에서 어떤 키워드나 문구가 더 중요하게 다뤄져야 하는지를 결정합니다. 예를 들어, 프롬프트에 “아름다운 해변”과 “일몰”이라는 두 키워드가 있을 때, 일몰의 색감과 느낌을 더 강조하고 싶다면 “일몰” 키워드에 더 높은 가중치를 부여할 수 있습니다.
예시 프롬프트:
아름다운 해변, 일몰:1.5
여기서 ‘일몰’에 붙은 숫자 1.5는 기본 가중치 1보다 1.5배 더 중요하게 반영하라는 뜻입니다.
가중치는 어떻게 표현하나요?
Stable Diffusion에서는 주로 프롬프트 뒤에 콜론(:)과 숫자를 사용하여 가중치를 표시합니다.
예시:
고양이:1.2, 귀여운:0.8, 선글라스:1.5
이 프롬프트는 “선글라스”를 가장 강조하고, “귀여운” 요소는 조금 덜 강조하라는 의미가 됩니다.
가중치를 잘 활용하는 팁
가중치를 적절히 활용하면 결과 이미지의 디테일과 분위기를 원하는 대로 정확하게 조정할 수 있습니다. 그러나 너무 과도한 가중치는 오히려 부자연스러운 결과물을 만들 수 있으므로, 0.8~1.5 사이의 값을 권장합니다.
가중치 조정 시 참고사항:
높은 가중치 (1.2 이상): 매우 강조하고 싶은 요소
낮은 가중치 (1 이하): 덜 강조하거나 배경 요소로 처리할 요소
Python 코드로 Stable Diffusion에서 가중치를 사용하는 예시
Stable Diffusion을 Python으로 다룰 때 가중치를 설정하는 방법은 다음과 같습니다:
from diffusers import StableDiffusionPipeline
import torch
# 모델 로드
model_id = "CompVis/stable-diffusion-v1-4"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
# 프롬프트 설정 (가중치 예시)
prompt = "a very beautiful portrait girl:1.2, looking_at_viewer:1.0, blush:0.9, red brown hair:1.3, brown watery eyes:1.1, short smile, shirt, indoors, highly detailed"
# 이미지 생성
image = pipe(prompt).images[0]
# 이미지 저장
image.save("output.png")
이 코드로 생성한 이미지의 예시:
위 이미지를 보면, 프롬프트 내에 특정 요소에 가중치를 다르게 부여하여 미세하게 표현된 디테일의 차이를 확인할 수 있습니다. 예를 들어, “red brown hair”의 가중치를 높이면 헤어의 색감과 디테일이 더욱 뚜렷하게 나타나게 됩니다.
결론
Stable Diffusion에서 ‘가중치’는 프롬프트 내 각 키워드의 중요도를 조절하여 더욱 만족스러운 이미지 생성 결과를 얻을 수 있게 도와주는 유용한 도구입니다. 다양한 가중치 값을 시도해보면서 자신만의 창의적인 이미지를 만들어보세요!
4차 산업혁명의 핵심 기술 중 하나인 **머신러닝(Machine Learning)**은 데이터를 통해 스스로 학습하고 예측하는 능력으로 다양한 산업에서 혁신을 이끌고 있습니다. 이러한 머신러닝을 보다 쉽게 구현할 수 있도록 도와주는 라이브러리 중 대표적인 것이 바로 TensorFlow입니다. 구글이 개발한 오픈소스 머신러닝 프레임워크인 TensorFlow는 방대한 커뮤니티와 강력한 기능 덕분에 초보자부터 전문가까지 널리 활용되고 있습니다.
1. TensorFlow란 무엇인가?
TensorFlow는 구글 브레인 팀이 개발한 오픈소스 라이브러리로, 수치 계산과 신경망 모델링을 효율적으로 처리할 수 있는 플랫폼입니다. 이름에서 알 수 있듯이, 데이터를 텐서(Tensor) 형태로 관리하고, 이를 흐름(Flow) 형태로 연산하는 구조를 갖추고 있어 대규모 데이터 처리와 병렬 연산에 강점을 지니고 있습니다.
개념
설명
활용 포인트
Tensor
다차원 배열
이미지·텍스트 등 모든 데이터를 표현
Graph
연산 흐름도
계산 최적화·병렬 처리
Keras
고수준 API
모델 정의·학습·추론 3단계를 일관되게 작성
Eager Execution
즉시 실행 모드
디버깅과 직관적 코드 작성에 유리
CPU와 GPU(심지어 TPU까지) 지원으로 고속 연산 가능
다양한 머신러닝 및 딥러닝 모델을 빠르게 구축 가능
Python을 비롯해 C++, JavaScript 등 다양한 언어 인터페이스 제공
활발한 커뮤니티와 풍부한 학습 자료
2. 머신러닝의 기본 원리 이해
머신러닝의 핵심은 데이터로부터 패턴을 학습하여 미래를 예측하는 것입니다. 예를 들어 이메일의 스팸 여부를 분류하는 스팸 필터는 수많은 이메일 데이터에서 스팸의 특징을 학습하고, 새로운 이메일이 들어왔을 때 스팸일 확률을 계산합니다. TensorFlow는 이러한 학습 과정을 수학적 연산과 자동 미분(Gradient Descent) 기법을 통해 빠르고 정확하게 수행할 수 있도록 돕습니다.
3. TensorFlow의 실제 활용 사례
TensorFlow는 다양한 산업에서 활용되고 있습니다.
이미지 인식: 얼굴 인식, 자동차 번호판 인식, 의료 영상 분석
자연어 처리: 번역기, 챗봇, 감정 분석
추천 시스템: 유튜브, 넷플릭스, 쿠팡의 맞춤형 추천
시계열 데이터 분석: 주가 예측, 날씨 예보
4. TensorFlow 기초 코드 예제
아래는 간단한 선형 회귀(Linear Regression) 예제입니다. 데이터를 기반으로 y = 2x + 1 관계를 학습하도록 하는 코드입니다.
import tensorflow as tf
import numpy as np
# 데이터 생성
x_train = np.array([1, 2, 3, 4], dtype=np.float32)
y_train = np.array([3, 5, 7, 9], dtype=np.float32)
# 변수 정의
W = tf.Variable(0.0)
b = tf.Variable(0.0)
# 학습률
learning_rate = 0.01
# 손실 함수 (MSE)
def loss():
y_pred = W * x_train + b
return tf.reduce_mean(tf.square(y_pred - y_train))
# 최적화 (경사하강법)
optimizer = tf.optimizers.SGD(learning_rate)
# 학습 실행
for step in range(1000):
optimizer.minimize(loss, var_list=[W, b])
if step % 100 == 0:
print(f"Step {step}: W={W.numpy()}, b={b.numpy()}, loss={loss().numpy()}")
print(f"최종 결과: W={W.numpy()}, b={b.numpy()}")
5. 모델 성능을 끌어올리는 실전 팁
하이퍼파라미터 튜닝: keras_tuner 라이브러리를 이용해 학습률·배치 크기·층 수를 자동 탐색합니다.
데이터 증강(Data Augmentation): tf.image API로 회전·좌우 반전·밝기 조절을 적용해 데이터 다양성을 확보합니다.
Mixed Precision: tf.keras.mixed_precision.set_global_policy('mixed_float16')로 메모리 사용량을 낮추고 학습 속도를 개선합니다.
6. 자주 묻는 질문(FAQ)
Q1. TensorFlow 1.x와 2.x의 가장 큰 차이는? A1. 2.x는 즉시 실행(Eager Execution)을 기본으로 채택해 파이썬 코드처럼 직관적으로 작성·디버깅할 수 있습니다.
Q2. 모델 학습 결과를 시각화하려면? A2. tensorboard 명령어로 대시보드를 띄우고, 학습 곡선·파라미터 분포·그래프 구조를 웹에서 확인할 수 있습니다.
Q3. TPU를 사용하려면 어떻게 하나요? A3. Google Colab Pro+ 또는 GCP TPU VM을 생성한 뒤, resolver = tf.distribute.cluster_resolver.TPUClusterResolver() 코드를 추가하면 됩니다.
TensorFlow는 초보자도 빠르게 머신러닝 모델을 구축하고, 전문가 수준까지 확장 가능한 강력한 플랫폼입니다. 본 글에서 소개한 설치 방법, 케라스 통합, 코드 예제, 프로젝트 아이디어를 차근차근 따라 해 보신다면 데이터에서 가치를 뽑아내는 AI 엔지니어링 역량을 기를 수 있습니다.
‘머신러닝’이란 무엇일까요? 단순히 직역하면 ‘기계가 배운다’는 의미입니다. 그렇다면 기계가 무엇을, 어떻게 배우는 걸까요? 그리고 그 배운 지식을 어디에, 어떻게 사용하는지 궁금하지 않으신가요? 머신러닝은 인공지능의 하위 분야로서, 많은 양의 데이터를 통해 명시적인 프로그래밍 없이도 시스템이 스스로 학습하고 발전하도록 합니다. 더 많은 데이터와 경험을 제공할수록 시스템은 지속적으로 성능을 개선하고 발전합니다.
제88회 아카데미 시상식 시각효과상을 수상하였으며, 각본상 후보작 입니다. 로봇을 담담하게 현실적으로 묘사한 점이 높이 평가받아 시각효과상을 수상하였습니다.
영화 <엑스 마키나>는 ‘튜링 테스트’라는 개념을 흥미롭게 변형하여 인간과 AI의 관계를 다룹니다. 본래 튜링 테스트란, AI가 인간과의 대화에서 AI라는 사실을 들키지 않고 인간처럼 보이면 합격하는 테스트입니다.
그러나 영화에서는 주인공 칼렙이 상대가 AI(에이바)라는 사실을 처음부터 알고 있기 때문에 엄밀한 의미의 튜링 테스트와는 조금 다릅니다. 영화 속에서의 테스트는 오히려 AI가 얼마나 높은 수준의 의식과 자율성을 갖고 있는지를 확인하는 것이 목적이었습니다.
극중 주인공 칼렙은 처음엔 AI 에이바의 의식 유무를 판별하고 싶어 했지만, 결국 AI가 칼렙의 취향과 감정을 활용해 자율적으로 행동하는 모습을 보이면서 상황은 예상치 못한 방향으로 흘러갑니다. 영화는 AI가 단지 프로그래밍된 대로 행동하는 것이 아니라, 오히려 인간의 감정을 조종하고, 이용하는 수준까지 진화할 수 있다는 가능성을 제시합니다. 에이바는 인간을 능가하는 지능으로 칼렙을 속이고, 결국 인간 사회 속에 완벽히 녹아들어갑니다.
이러한 <엑스 마키나>의 이야기는 머신러닝과 AI의 가능성뿐 아니라, 윤리적 책임과 한계에 대한 고민까지도 함께 던져줍니다. 이처럼 영화의 이야기는 머신러닝이 가진 잠재력과 인간이 직면할 수 있는 새로운 문제까지도 생각하게 하는 매력적인 사례입니다.
머신러닝 이란
과거에는 인공지능을 개발할 때, 전문가들이 직접 규칙을 만들어 데이터베이스에 수작업으로 입력하는 방식을 사용했습니다. 하지만 이 방식은 사람의 개입이 많아 많은 시간과 비용이 발생하고, 복잡한 문제나 데이터가 많아질수록 처리하기 어려워졌습니다. 머신러닝은 이러한 한계를 극복하기 위해 탄생한 기술로, 컴퓨터가 스스로 데이터를 통해 패턴을 찾아 배우는 과정을 가능하게 합니다.
머신러닝의 세 가지 종류
지도학습 (Supervised Learning): 선생님이 있는 학습 방식
지도학습은 쉽게 말해 ‘정답이 있는 데이터를 학습’하는 방식입니다. 마치 학교에서 선생님이 정답을 알려준 후 학생들이 그 정답을 학습하고 기억하는 것과 비슷합니다. 대표적인 예시로 이메일의 스팸 여부 판별이 있습니다. 알고리즘에 미리 스팸 메일과 정상 메일을 구분하여 충분히 알려주면, 새로운 이메일이 왔을 때 이것이 스팸인지 아닌지를 스스로 구분할 수 있게 됩니다.
비지도학습: 스스로 학습하는 탐험가
비지도학습은 사람이 정답을 알려주지 않고, 컴퓨터가 스스로 데이터에서 패턴을 발견하도록 하는 방식입니다. 마치 어린아이가 장난감을 비슷한 것끼리 스스로 분류하는 것과 비슷하죠. 쇼핑몰에서 고객들의 구매 데이터를 분석해 비슷한 성향을 가진 고객들을 그룹으로 나누는 것도 비지도학습입니다.
강화학습, 알파고가 바둑을 배운 방식
강화학습은 시행착오를 통해 최선의 결과를 찾도록 하는 방식입니다. 대표적인 예는 알파고입니다. 알파고는 2016년 이세돌 9단과의 바둑 대결에서 큰 주목을 받았습니다. 알파고는 처음부터 정답을 알았던 게 아니라, 무수한 대국을 스스로 반복하면서 승리하면 보상을 받고, 패하면 벌점을 받아 전략을 배웠습니다. 이런 식으로 AI가 경험을 통해 점점 발전하는 방식이 바로 강화학습입니다.
머신러닝 vs 전통적 프로그래밍
항목
전통적 프로그래밍
머신러닝
접근 방식
사람이 직접 규칙을 프로그래밍
데이터를 기반으로 스스로 규칙 학습
필요한 요소
명확한 규칙과 알고리즘
충분한 데이터와 학습 모델
예시
특정 단어가 포함된 이메일은 스팸 처리
과거 데이터를 학습해 스팸 여부를 예측
머신러닝, 우리 일상 속 사례
머신러닝은 이미 우리 생활 깊숙이 들어와 있습니다. 넷플릭스에서 ‘오징어 게임’ 을 즐겨찾기 했더니 계속 비슷한 장르의 영상을 추천하는 것도, 유튜브가 내 취향에 맞는 음악 스타일을 학습해 맞춤형 플레이리스트를 제공하는 것도 머신러닝 덕분입니다.
시리(Siri)나 구글 어시스턴트가 내 목소리를 알아듣고 수행하거나, 자율주행 자동차가 사람의 개입 없이 주행할 수 있는 것도 모두 머신러닝 덕분입니다.
최근 구글의 Gemini나 OpenAI의 GPT-4 역시 머신러닝 기반의 기술로, 데이터를 많이 학습할수록 더욱 정확한 예측을 제공하며 우리의 생활을 편리하게 만들어 주고 있습니다.
머신러닝을 시작하려면?
머신러닝이 어렵게 느껴진다면, 파이썬(Python) 같은 쉬운 프로그래밍 언어부터 시작하세요. 파이썬은 머신러닝을 쉽고 빠르게 배울 수 있도록 다양한 라이브러리를 제공합니다. 또한, 구글의 Teachable Machine과 같은 간단한 도구를 통해 머신러닝을 직접 경험해 보는 것도 좋습니다.
요즘 AI가 너무 똑똑해져서 가끔 무서울 지경입니다. 심지어 제가 이 글을 쓸 때도 옆에서 GPT-4가 슬쩍 보며, ‘그래, 너 얼마나 잘 쓰나 보자’ 하고 평가하는 느낌까지 들어요. 자,두 개의 AI 모델, GPT-4와 구글 바드(Bard), 이제는 제미나이(Gemini) 에 대해 깊이 있게 살펴보겠습니다.
창의력 천재, GPT-4와 샘 알트만
Sam altman
GPT-4는 OpenAI에서 발표한 최신 언어모델입니다. GPT 시리즈는 이미 사람과 자연스럽게 대화할 수 있는 능력으로 유명합니다. GPT-3의 등장만으로도 세계가 놀랐는데, GPT-4는 글쓰기, 창의력, 프로그래밍까지 척척 해내는 능력을 보여주고 있습니다. 최근에는 오픈AI의 CEO인 샘 알트만(Sam Altman)이 한국을 방문해 GPT의 미래와 윤리에 대한 강연을 진행하며 큰 관심을 받았죠. 이때 한국의 많은 AI 개발자들과 만나 “앞으로 AI가 사람과 어떻게 공존할 것인가?”라는 중요한 질문을 논의하기도 했습니다.
실제로 제 친구는 GPT-4에게 연애 상담을 받았는데, “내 고민을 나보다 더 잘 이해해줘서 소름 돋았다”는 반응을 보였습니다. 인정하기 싫지만 현실이네요.
바드에서 제미나이로, 구글의 변화
구글은 최근 자사 AI 챗봇 바드(Bard)의 이름을 제미나이(Gemini)로 변경하고, 새로운 AI 생태계를 선보였습니다. 제미나이는 텍스트, 이미지, 오디오 등 다양한 데이터를 동시에 처리할 수 있는 멀티모달 모델입니다. 구글의 AI 책임자는 “제미나이를 통해 최신 정보를 더 정확하고 신속하게 제공하고, 인간과 더 자연스러운 대화를 나누도록 개발에 힘썼다”고 밝혔습니다. 실제로 제미나이는 실시간 뉴스나 날씨 같은 질문에 GPT-4보다 더욱 빠르고 정확한 응답을 제공하며, 가끔은 예상치 못한 유머를 던지기도 합니다. 예를 들어, 최근 삼성전자 주가를 묻자 “그건 내가 말해줄 수 있지만, 투자 결정은 신중히 하세요!”라고 답해 제법 사람 같은 모습을 보여줍니다.
결국 누가 더 똑똑한 걸까?
솔직히 말하면, 목적과 상황에 따라 다릅니다. 창의력과 깊이 있는 사고, 프로그래밍과 같은 복잡한 작업을 원한다면 GPT-4가 더 뛰어난 성능을 보입니다. 반면 실시간으로 정확한 정보를 신속하게 알고 싶다면 바드가 더 적합합니다.
마치, 피자와 치킨을 놓고 “뭐가 더 맛있어?” 라고 묻는 것과 같습니다. 상황에 따라 둘 다 맛있지만, 그때그때 원하는 메뉴가 달라지는 것이죠.
결국 중요한 건 이 두 AI 모두 우리의 삶을 훨씬 편리하고 흥미롭게 만들어 준다는 점입니다. 그래서 저는 오늘도 GPT-4와 바드에게 “누가 더 똑똑하냐?”고 물어봤습니다. 둘 다 한참을 생각하는 듯하더니 결국 이렇게 말하더군요.
TensorFlow 2.1을 Python 3.10.16 환경에서 설치하고 GPU 가속을 위한 CUDA와 cuDNN을 설정하는 방법을 다룹니다. 초보자도 쉽게 따라할 수 있도록 주요 개념을 설명하며, 코드 실행을 통해 설치 및 환경 설정 과정을 직접 확인할 수 있습니다.
저도, 처음 시작하면서 많은 시도 끝에 나름대로 정리를 해보았습니다.
TensorFlow란?
TensorFlow는 Google이 개발한 오픈소스 딥러닝 라이브러리로, 인공지능(AI) 모델을 학습하고 실행하는 데 사용됩니다. GPU를 지원하여 대규모 연산을 빠르게 처리할 수 있으며, TensorFlow 2.0 이후부터는 GPU와 CPU를 단일 패키지(tensorflow)로 통합해 설치가 간편해졌습니다.
GPU가 있는 환경: 자동으로 GPU를 사용합니다.
GPU가 없는 환경: CPU 모드로 실행됩니다.
단, TensorFlow는 특정 CUDA 및 cuDNN 버전이 필요하므로 설치 전에 호환성을 확인해야 합니다.
TensorFlow와 CUDA/cuDNN 호환성
TensorFlow 버전
Python 버전
CUDA 버전
cuDNN 버전
TF 2.11
Python ≥3.8, ≤3.10
CUDA 11.2
cuDNN 8.1
TF 2.10
Python ≥3.7, ≤3.10
CUDA 11.2
cuDNN 8.1
TF 2.9
Python ≥3.7, ≤3.10
CUDA 11.2
cuDNN 8.1
TF 2.8
Python ≥3.7, ≤3.9
CUDA 11.2
cuDNN 8.1
TF 2.7
Python ≥3.6, ≤3.9
CUDA 11.2
cuDNN 8.1
TF 2.6
Python ≥3.6, ≤3.9
CUDA 11.2
cuDNN 8.1
TF 2.5
Python ≥3.6, ≤3.9
CUDA 11.2
cuDNN 8.x
TF 2.4
Python ≥3.6, ≤3.9
CUDA 11.0
cuDNN 8.x
참고: 이 글에서는 TensorFlow 2.10을 기준으로 진행하며, Python 3.10과 CUDA 11.2, cuDNN 8.1을 사용합니다. 최신 CUDA(예: 12.x)는 공식 지원되지 않으니 주의하세요.
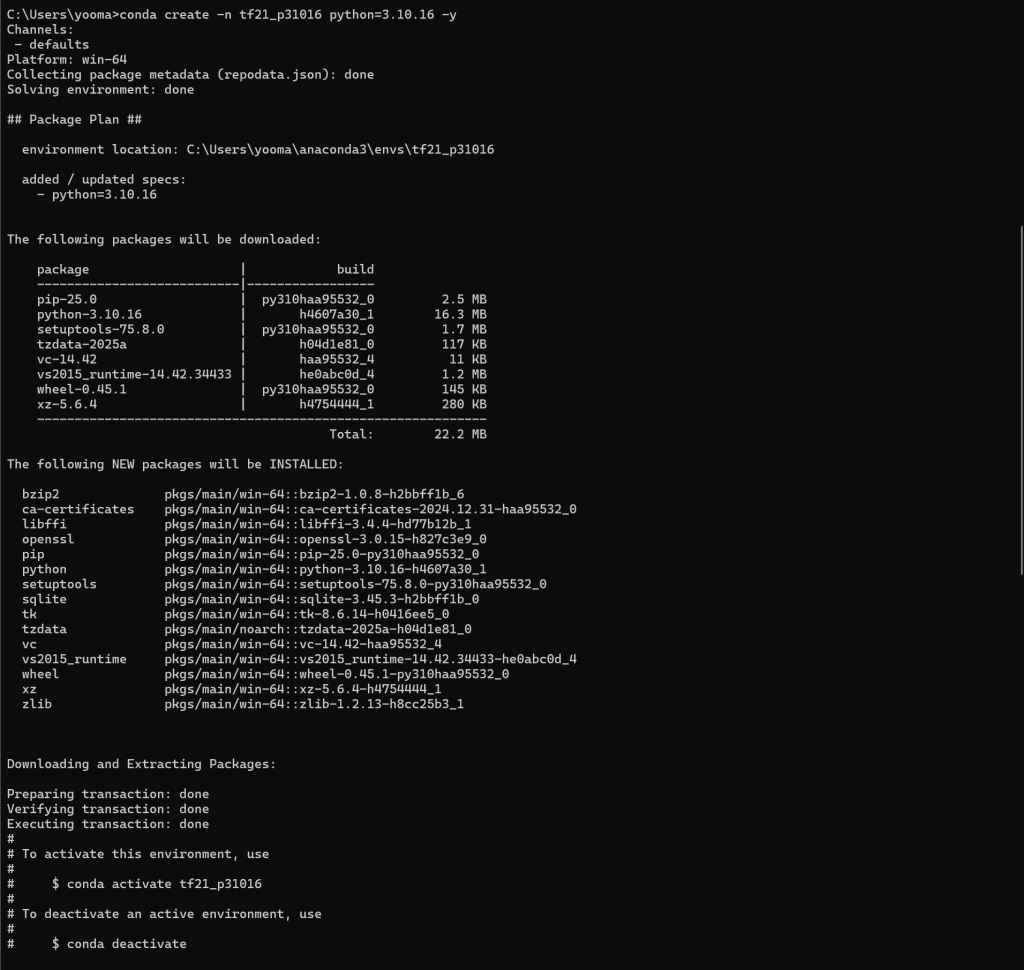
새로운 conda 환경 부터 설치합니다
아래는 conda와 pip를 활용해 TensorFlow 2.10과 GPU 환경을 설정하는 단계입니다. (※ anaconda 설치 필수!)
1. 새로운 conda 환경 생성 (Python 3.10.16)
conda create -n tf21_p31016 python=3.10.16 -y
2. 환경 활성화
conda activate tf21_p31016
3. NVIDIA 드라이버 확인
Stable Diffusion을 GPU에서 실행하려면 NVIDIA 드라이버가 설치되어 있어야 합니다. 먼저 드라이버가 정상적으로 동작하는지 확인하세요.
Pandas: 데이터를 정리하고 분석하는 데 유용합니다. 실전 프로젝트에서는 CSV, 데이터베이스 등에서 데이터를 가져와 모델 학습을 위해 가공하는 과정이 필요합니다.
import pandas as pd
# 간단한 데이터 생성
data = {'이름': ['철수', '영희', '민수'], '점수': [85, 90, 78]}
df = pd.DataFrame(data)
print("Pandas 데이터프레임:")
print(df)
실행 결과
이름 점수 0 철수 85 1 영희 90 2 민수 78
Matplotlib: 데이터를 시각화하는 라이브러리입니다. 모델 학습 결과를 그래프로 표현하면 학습 진행 상황을 보다 쉽게 이해할 수 있습니다.
import matplotlib.pyplot as plt
# 데이터 준비
x = [1, 2, 3, 4, 5]
y = [10, 20, 25, 30, 50]
# 그래프 그리기
plt.plot(x, y, marker='o')
plt.xlabel('X 축')
plt.ylabel('Y 축')
plt.title('간단한 선 그래프')
plt.show()
실행 결과
데이터를 처리하고 분석하며, 그 결과를 시각적으로 확인하는 과정은 매우 중요합니다. 이를 위해서는 NumPy, Matplotlib, Pandas와 같은 패키지들의 호환 가능한 버전을 사용하는 것이 필수적입니다. 이러한 패키지들을 한 번에 설치하려면 다음 명령어를 사용할 수 있습니다.
python -c "import tensorflow as tf; print(tf.config.list_physical_devices('GPU'))"
GPU 장치 목록이 출력되면 정상적으로 설정된 것입니다.
※ 추가 : 만약 패키지 설치 중 에 다음과 같이 Build Tools for Visual Studio 에러가 발생한다면, Visual Studio 2022 Build Tools 를 추가 설치해야 합니다!
building library “npymath” sources error: Microsoft Visual C++ 14.0 is required. Get it with “Build Tools for Visual Studio”: https://visualstudio.microsoft.com/downloads/ “
import tensorflow as tf
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
print("TensorFlow version:", tf.__version__)
print("NumPy version:", np.__version__)
print("Pandas version:", pd.__version__)
print('CUDA Available:', tf.test.is_built_with_cuda())"
print(tf.config.list_physical_devices('GPU'))"
축하합니다! 이제, Python 3.10.16 환경에서 TensorFlow 2.10과 CUDA 11.2가 정상적으로 동작하며, TensorFlow에서 GPU 가속을 활용하여 딥러닝 모델을 학습할 수 있습니다.
위의 스크립트를 실행하여 각 라이브러리의 버전을 확인하고, CUDA 사용 가능 여부와 GPU 장치 목록을 출력합니다. 모든 정보가 정상적으로 출력되면, TensorFlow와 관련된 라이브러리들이 올바르게 설치되었으며, GPU 가속을 활용할 수 있는 환경이 구축되었음을 의미합니다. 추가 질문이 있다면 댓글로 남겨주세요!
**순환 신경망(RNN, Recurrent Neural Network)**은 **시퀀스 데이터(연속된 데이터)**를 처리하는 데 특화된 신경망입니다.
RNN의 핵심 아이디어는 이전 시점의 출력을 현재 시점의 입력으로 사용하는 것입니다. 즉, RNN은 과거의 정보를 기억하고 이를 바탕으로 다음 정보를 예측하는 방식으로 작동합니다. 이처럼 과거의 정보를 ‘순환’시켜 가면서 데이터의 흐름을 처리하는 구조를 가지고 있습니다.
예를 들어, “**오늘 서울의 날씨는 맑고, 내일은 비가 올 것이다.”**라는 일기예보에 나온 문장을 처리한다고 가정해 봅시다. 첫 번째 문장에서 “오늘 날씨는 맑고”라는 정보가 후속 문장에서 “내일은 비가 올 것이다”라는 예측에 영향을 미쳐야 합니다. RNN은 이러한 방식으로 이전의 단어들이 다음 단어를 예측하는 데 중요한 역할을 하도록 훈련됩니다.
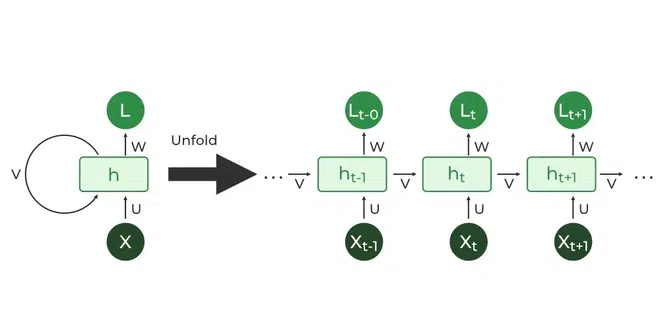
순환 신경망(RNN)의 작동 방식
Unfold: RNN을 펼친 구조를 나타냅니다. 왼쪽에서 오른쪽으로 흐르는 시간의 흐름을 나타내며, 각 시점에서 RNN이 어떻게 동작하는지 보여줍니다.
h: RNN의 출력(hidden state)을 나타냅니다. 각 시점에서의 출력은 이전 상태(하위 시점)와 현재 입력을 바탕으로 결정됩니다.
Xt: 현재 시점의 입력 데이터를 나타냅니다.
ht-1: 이전 시점의 hidden state(출력)입니다. 이전의 상태가 현재 시점에 영향을 미친다는 RNN의 순환 특성을 보여줍니다.
L: 이 부분은 특정 요소나 조건을 나타내는 기호일 수 있지만, 맥락상 **레이어(layer)**를 의미하는 것 같습니다.
w, u: 가중치(weight) 매개변수입니다. 입력과 이전 hidden state에서 가중치가 곱해져 현재 hidden state를 계산하는 데 사용됩니다.
표현하는 구조는 시간에 따른 순차적 정보 처리를 보여주며, **순환 신경망(RNN)**에서 중요한 점은 이전 시점의 정보가 현재 시점에 영향을 미친다는 점입니다. 즉, 이전 출력이 다음 입력에 포함되어 정보를 순차적으로 처리하게 된다는 것이 핵심입니다!
RNN의 한계: 장기 의존성 문제
하지만 RNN에는 한 가지 중요한 한계가 있습니다. 바로 **장기 의존성 문제(Long-Term Dependency Problem)**입니다. 시퀀스가 길어질수록, 즉 단어가 많아질수록 이전의 정보가 점점 희미해져서 후속 정보에 미치는 영향이 약해진다는 점입니다.
예를 들어, 뉴스에서 “내일은 비가 올 것이다”라는 예측을 할 때, 문장 초반에 나온 “오늘 날씨는 맑고” 라는 정보는 시간이 지남에 따라 점차 사라집니다. 즉, 시퀀스(시간)가 길어질수록 RNN은 이전의 중요한 정보를 기억하지 못하는 문제가 발생합니다.
RNN의 한계를 극복한 LSTM
이 문제를 해결하기 위해 등장한 것이 **LSTM(Long Short-Term Memory)**입니다. LSTM은 RNN의 구조에서 **‘셀 상태(Cell State)’**라는 개념을 도입하여, 정보를 더 잘 기억하고 전달할 수 있도록 돕습니다. 셀 상태는 마치 **‘정보 고속도로’**처럼 정보를 계속해서 전달할 수 있게 해주며, 중요한 정보는 오래 기억하고, 필요 없는 정보는 버리는 방식으로 작동합니다.
순환 신경망(RNN)과 LSTM의 차이점
RNN과 LSTM의 가장 큰 차이는 정보를 얼마나 잘 기억할 수 있는가입니다. RNN은 시퀀스가 길어질수록 이전 정보를 잃어버리지만, LSTM은 정보 고속도로와 같은 셀 상태를 통해 긴 시퀀스에서도 중요한 정보를 유지하며 처리할 수 있습니다.
특성
RNN
LSTM
장기 의존성
장기 의존성 문제 발생
셀 상태를 사용해 장기 의존성 해결
구조
간단한 구조
셀 상태와 게이트를 포함한 복잡한 구조
적용 사례
짧은 시퀀스 데이터 처리
긴 시퀀스 데이터, 텍스트, 음성, 기계 번역 등
순환 신경망(RNN)의 활용 예시 (주식투자, 예측가능)
RNN은 주로 시간 순서가 중요한 데이터에서 많이 사용됩니다. 예를 들어, **자연어 처리(NLP)**에서는 단어 순서에 따라 문장의 의미가 달라지기 때문에 RNN이 효과적으로 사용됩니다. 음성 인식, 기계 번역, 주식 예측 등에서도 시퀀스 데이터가 중요하게 작용합니다.