“지적 노동에서 전문가를 넘는다”는 말은 과장이었을까
OpenAI가 2025년 12월, 최신 AI 모델 GPT-5.2를 공개했다.
OpenAI는 이 모델을 “전문 지식 노동과 장시간 에이전트 작업을 위한 가장 진보한 프런티어 모델”이라고 설명한다.
이 문장은 익숙하다.
AI 발표 때마다 반복되어 온 표현이기 때문이다.
하지만 GPT-5.2에 대해 업계가 주목하는 이유는 따로 있다.
이번에는 “더 똑똑해졌다”는 선언이 아니라, 이미 경제적 효과가 수치로 증명되고 있다는 점이다.

이미 업무 시간은 줄어들고 있었다
OpenAI에 따르면,
평균적인 ChatGPT Enterprise 사용자는 이미 하루 40~60분의 시간을 절약하고 있으며,
헤비 유저의 경우 주당 10시간 이상을 AI로 절감하고 있다고 답했다.
GPT-5.2는 이 지점을 더 밀어붙이기 위해 설계됐다.
- 스프레드시트 생성
- 프레젠테이션 구성
- 코드 작성과 리뷰
- 이미지 이해
- 긴 문맥 분석
- 도구 호출과 다단계 프로젝트 처리
즉, GPT-5.2는 “답변을 잘하는 모델”이 아니라
실제 결과물을 만들어내는 모델에 가깝다.
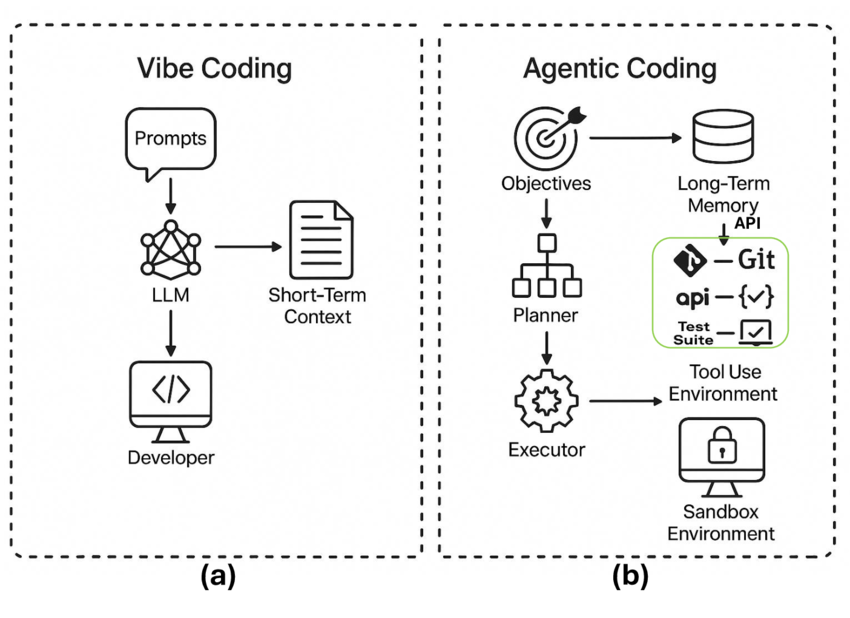
GPT-5.2는 하나의 모델이 아니다
GPT-5.2는 용도에 따라 세 가지로 제공된다.
- GPT-5.2 Instant
일상 업무, 학습, 검색, 설명에 최적화된 고속 모델 - GPT-5.2 Thinking
복잡한 추론, 코드, 장문 문서, 다단계 의사결정을 위한 모델 - GPT-5.2 Pro
시간이 걸리더라도 정확성과 완성도를 최우선으로 하는 최상위 모델
이 구성은 OpenAI의 전략 변화를 보여준다.
“하나의 AI가 모든 것을 한다”는 환상에서,
업무 흐름에 맞춘 AI 분업 체계로 이동하고 있다는 신호다.
GPT-5.2 Thinking과 Pro는 실제로 얼마나 강해졌나
GPT-5.2에 대한 설명이 추상적으로 느껴진다면,
이제는 숫자를 볼 차례다.
OpenAI는 GPT-5.2 Thinking을 중심으로,
GPT-5.2 Pro의 일부 결과를 포함한 세부 벤치마크 점수를 공개했다.
이 평가는 단순 정답률이 아니라, 실제 업무·연구·엔지니어링 맥락을 기준으로 설계된 것이 특징이다.
전문 지식 노동 (Professional Work)
| 평가 항목 | GPT-5.2 Thinking | GPT-5.2 Pro | 이전 세대 |
|---|---|---|---|
| GDPval (승·무 기준) | 70.9% | 74.1% | 38.8% (GPT-5) |
| GDPval (명확한 승리만) | 49.8% | 60.0% | 35.5% |
| 투자은행 스프레드시트 과제 | 68.4% | 71.7% | 59.1% |
이 수치는 의미가 명확하다.
GPT-5.2 Thinking은 이미 다수의 지식 노동 과제에서 인간 전문가와 동급 이상이며,
Pro 모델은 그 안정성과 완성도를 더 끌어올린다.
특히 스프레드시트, 재무 모델링, 프레젠테이션 구성처럼
형식과 구조가 중요한 업무에서 개선 폭이 크다.
코딩 성능 (Coding)
| 평가 항목 | GPT-5.2 Thinking | GPT-5.2 Pro | GPT-5.1 Thinking |
|---|---|---|---|
| SWE-Bench Pro (Public) | 55.6% | – | 50.8% |
| SWE-bench Verified | 80.0% | – | 76.3% |
| SWE-Lancer IC Diamond | 74.6% | – | 69.7% |
SWE-Bench Pro는 실제 코드 저장소를 기반으로
“패치를 만들어 문제를 해결할 수 있는지”를 평가한다.
GPT-5.2 Thinking은 여기서 **새로운 최고점(SOTA)**을 기록했다.
이는 곧,
- 대규모 코드베이스 리팩토링
- 기능 구현
- 버그 수정
같은 작업을 사람의 개입 없이 끝까지 밀고 갈 확률이 높아졌다는 뜻이다.
사실성 (Factuality)
| 평가 항목 | GPT-5.2 Thinking | GPT-5.1 Thinking |
|---|---|---|
| 오류 없는 응답 (검색 사용) | 93.9% | 91.2% |
| 오류 없는 응답 (검색 없음) | 88.0% | 87.3% |
숫자 차이는 크지 않아 보이지만,
업무 현장에서는 이 2~3%가 재검토 비용과 신뢰도를 크게 바꾼다.
GPT-5.2는 “더 똑똑한 AI”라기보다
“덜 틀리는 AI”에 가까워졌다고 보는 편이 정확하다.
초장문 문맥 이해 (Long Context)
| 평가 항목 | GPT-5.2 Thinking | GPT-5.1 Thinking |
|---|---|---|
| MRCRv2 (8 needles, 4k–8k) | 98.2% | 65.3% |
| MRCRv2 (16k–32k) | 95.3% | 44.0% |
| MRCRv2 (128k–256k) | 77.0% | 29.6% |
이 결과는 매우 상징적이다.
GPT-5.2는 256k 토큰 구간에서도 논리 붕괴 없이 정보를 유지한다.
즉, 이제 AI는
- 계약서 수십 개
- 보고서 수백 페이지
- 대화 로그 전체
를 **“읽고, 기억하고, 다시 꺼내 쓸 수 있는 단계”**에 들어섰다.
비전(Vision) 이해
| 평가 항목 | GPT-5.2 Thinking | GPT-5.1 Thinking |
|---|---|---|
| CharXiv Reasoning (w/ Python) | 88.7% | 80.3% |
| ScreenSpot Pro (GUI 이해) | 86.3% | 64.2% |
GPT-5.2는 단순 이미지 인식을 넘어,
**“화면의 구조와 맥락”**을 이해하기 시작했다.
이는 기술 지원, 운영 대시보드 분석, UI 리뷰 같은
실무 영역에서 특히 강력하다.
수학·과학·추론
| 평가 항목 | GPT-5.2 Thinking | GPT-5.2 Pro | GPT-5.1 Thinking |
|---|---|---|---|
| GPQA Diamond | 92.4% | 93.2% | 88.1% |
| AIME 2025 | 100% | 100% | 94.0% |
| FrontierMath (Tier 1–3) | 40.3% | – | 31.0% |
| ARC-AGI-2 | 52.9% | 54.2% | 17.6% |
특히 ARC-AGI-2는 사전 지식이 통하지 않는 추상 추론 문제다.
여기서의 점프는 GPT-5.2가 단순 패턴 인식 모델을 넘어서
‘새 문제를 푸는 사고 구조’를 갖추기 시작했음을 보여준다.
이 숫자들이 말해주는 것
GPT-5.2는 모든 영역에서 “조금씩 좋아진 모델”이 아니다.
- 지식 노동 → 전문가 수준 도달
- 코딩 → 엔드투엔드 처리 가능
- 문맥 → 사고의 지속성 확보
- 비전 → 업무 화면 이해
- 추론 → 새 문제 대응
즉, GPT-5.2는
“AI를 어디까지 맡길 수 있는가”라는 질문에 처음으로 실질적인 답을 제시한 모델이다.
환각이 줄었다는 말의 무게
GPT-5.2 Thinking은 환각(hallucination) 발생률도 줄였다.
실제 ChatGPT 질의 기준으로,
오류가 포함된 응답은 약 30% 상대적으로 감소했다.
숫자만 보면 작아 보일 수 있다.
그러나 업무에서 이 차이는 치명적이다.
- 리서치
- 분석
- 의사결정 지원
이 영역에서 “조금 덜 틀린 AI”는
“훨씬 더 신뢰할 수 있는 AI”를 의미한다.
긴 문서, 이제는 진짜 ‘읽는다’
GPT-5.2 Thinking은 256k 토큰까지의 장문 문맥에서
거의 100%에 가까운 정확도를 기록했다.
계약서, 보고서, 연구 논문, 회의 기록처럼
수십만 토큰에 흩어진 정보를 하나의 논리로 엮는 작업이 가능해졌다.
이는 단순한 컨텍스트 확장이 아니라,
사고의 지속성이 확보됐다는 의미다.
이미지와 화면을 이해하는 AI
GPT-5.2는 시각 인식에서도 큰 폭의 개선을 보였다.
- 과학 논문 차트 해석
- GUI 스크린샷 이해
- 대시보드, 다이어그램 분석
특히 화면 요소의 상대적 위치를 이해하는 능력이 향상되면서,
기술 지원, 디자인 검토, 엔지니어링 업무에서 활용도가 높아졌다.