Deep Learning 은 인간의 뇌에서 영감을 받은 인공 신경망을 사용하여 컴퓨터가 학습하는 머신 러닝 의 방법 중 하나로, 음악을 만들거나, 우리가 오렌지와 사과를 보고 각각 다른 과일이라고 인식할 수 있는 것 처럼 컴퓨터가 사진이나 사물을 보고 이해할 수 있거나 언어를 이해하는 방법을 학습 하는 것이라고 정의할 수 있습니다. ‘Deep’ 이라는 단어는 신경망에 여러 층(레이어)을 쌓아 깊게 만든다는 의미입니다. 이러한 깊은 네트워크를 통해 컴퓨터는 복잡한 문제를 해결하는 데 필요한 패턴이나 관계를 스스로 찾아낼 수 있습니다. 딥러닝은 이미지 인식, 음성 인식, 자연어 처리 등 다양한 분야에서 활용되고 있습니다.
Deep Learning (딥 러닝) 의 개념
간략히 딥러닝의 역사를 살펴보면, 가장 초기의 인공 신경망인 퍼셉트론(Perceptron)이 1958년에 제안되었습니다. 이후 1986년에 다층 퍼셉트론(Multilayer Perceptron)이 제안되고, 이를 학습시키는 방법인 역전파(Backpropagation) 알고리즘이 등장하면서 딥러닝의 기초가 마련되었습니다.
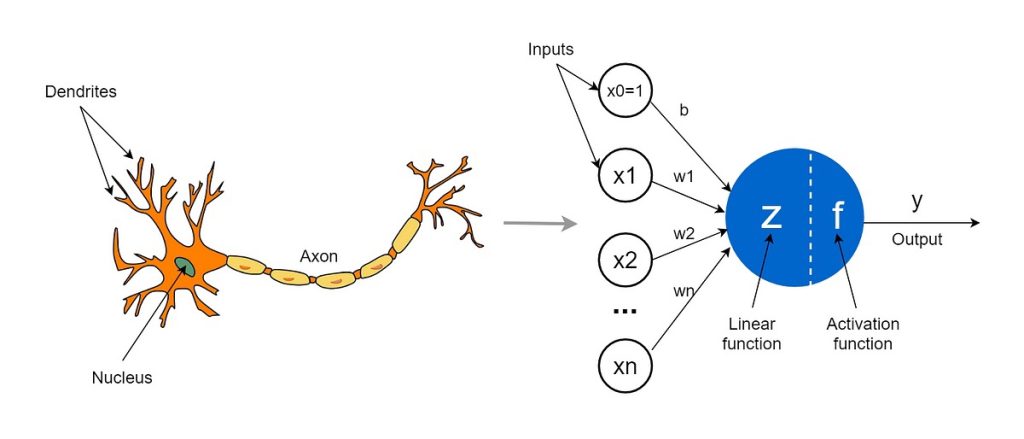
퍼셉트론은 간단한 문제를 해결하는 컴퓨터의 작은 뇌(Brain)와 같습니다. 모아진 퍼셉트론은 복잡한 문제도 해결할 수 있게 되는데, 이것이 바로 딥러닝, 즉 ‘깊은 학습’입니다. 인간의 뇌에는 “뉴런(Neuron)” 이 수억 개 있고, 이들이 함께 작동하여 생각하고, 느끼고, 기억하는 데 도움을 줍니다. 퍼셉트론은 이런 뉴런을 모방한 것으로, 간단한 계산을 수행하고 문제를 해결합니다.
뉴런과 퍼셉트론의 비교
뉴런은 덴드라이트(작은 섬유)를 통해 다른 뉴런으로부터 입력 신호를 받습니다. 마찬가지로, 퍼셉트론은 숫자를 받는 입력 뉴런을 통해 다른 퍼셉트론으로부터 데이터를 받습니다. 생물학적 뉴런에서, 출력 신호는 축삭에 의해 운반 됩니다. 마찬가지로, 퍼셉트론의 축삭은 다음 퍼셉트론의 입력이 될 출력 값 입니다. 덴드라이트와 생물학적 뉴런 사이의 연결 지점은 “시냅스” 라고 정의 합니다. 입력과 퍼셉트론 사이의 연결은 ”가중치“ 라고 정의 합니다. 그들은 각 입력의 중요성 수준을 측정 할 수 있는 지표가 됩니다. 뉴런에서, 핵은 덴드라이트가 제공하는 신호를 기반으로 출력 신호를 생성 합니다. 마찬가지로, 퍼셉트론의 핵(파란색)은 입력 값을 기반으로 몇 가지 계산을 수행하고 출력을 생성합니다.
딥러닝 개념이 시작한 초기에는 컴퓨터의 성능이 부족하여 복잡한 신경망을 학습시키기 어려웠습니다. 2000년대 초반에 들어서 GPU가 발전하고 빅 데이터가 확산되면서 딥러닝은 크게 주목받게 되었습니다. 이 중 2012년에 딥러닝 모델인 AlexNet이 이미지 인식 대회에서 우승하면서 딥러닝은 성능을 인정받게 되었습니다.
2016년에 세계 챔피언 이세돌 9단과 바둑 대국에서 승리하면서 전 세계적으로 주목 받았던 알파고는 Google의 딥마인드(DeepMind) 팀이 개발한 딥러닝과 강화학습 으로 탄생한 기술 입니다. 딥러닝은 바둑판의 상태를 해석하고 다음 수를 예측하는 데 사용되었고 강화학습은 알파고가 자기 자신과 게임을 하면서 수천만 개의 바둑 기보를 분석하고 스스로 학습하느여 어떤 수가 승리에 이르는 방법을 학습하여 바둑의 복잡성을 이해하고, 강화학습을 통해 전략을 최적화하여 인간과 바둑을 둘 수 있게 되었습니다.
딥러닝은 이미지 분석, 음성 인식, 자연어 처리 등 다양한 분야에서 뛰어난 성능을 보이며 머신러닝 분야의 주요한 연구 방향이 되고있습니다.
초등학교 코딩 교육은 디지털 시대에서 점점 더 중요해지고 있는 분야입니다. 2025년부터 초중고 코딩 교육 의무화 (YTN 기사 2022-11-10) 된다고 합니다. 이러한 결정은 앞으로 초등학교 코딩 교육의 필요성을 더욱 강조하고 있습니다.
초등학교 코딩교육의 필요성
코딩은 우리의 일상 생활과 산업에 깊숙이 뿌리를 내리고 있습니다. 인공지능 기술의 발전으로 chatGPT, Ai 로봇, Vr, 사물인식, 자율주행 자동차 등 혁신적인 기술들이 등장하고 있으며, 다양한 영역에서 기술 제품들은 모두 프로그램에 의해 작동되고 있습니다. 더욱더 발전될 다가오는 미래를 대비하고 우리가 이러한 기술들을 활용하기 위해서는 코딩을 이해하고 활용할 수 있는 능력이 필요합니다.
초등학생을 위한 코딩 교육 방법
디지털 시대에 살아가는 우리 아이들은 코딩을 배우는 것이 중요합니다. 그렇다면 초등학생들을 위한 코딩 교육 방법은 어떤 것이 있을까요?
코딩하는 컴퓨터
코딩은 한 번 배우면 끝나는 것이 아니고 실습과 반복을 통해 아이들은 코딩에 익숙해질수 있도록, 아이들 자신의 아이디어를 구현하고 실험해볼 수 있는 내용으로 구성하여 재미있고 흥미로운 주제로 접근해야 하며, 코딩을 배우면서 자신의 능력을 발휘할 수 있다고 강조하고, 미래를 준비하는데 꼭 필요하다고 알려주는 것도 중요 합니다.
초등학생을 위한 코딩 교육은 재미있고 게임 형식으로 진행되는 것이 좋다.
창의적인 문제 해결 능력과 아이디어를 실현할 수 있는 환경을 제공해야 한다.
협력과 소통을 강조하여 그룹 프로젝트나 팀 작업을 통한 문제 해결을 도모해야 한다.
코딩은 반복적인 실습을 통해 익숙해지고 자신의 아이디어를 구현할 수 있는 활동으로 구성되어야 한다.
코딩은 미래를 준비하는데 필요한 역량이며, 자신감과 흥미를 갖도록 지원과 제도를 마련해야 한다.
초등학교 코딩 교육의 장점과 효과
코딩 교육은 창의성과 협력을 키우는 데에도 도움이 됩니다. 코딩은 문제를 해결하기 위해 다양한 방법을 고민하고 실험하는 과정을 요구하며, 이를 통해 학생들은 자신의 아이디어를 구체화하고 다른 사람들과 협력하여 문제를 해결하는 방법을 배울 수 있습니다. 그룹 프로젝트를 통해 학생들은 함께 문제를 해결하고 아이디어를 공유하는 경험을 할 수 있으며, 이는 학생들의 협업과 소통 능력을 향상시키는 데에 도움이 됩니다.
또한, 코딩은 순차적인 단계를 따라가며 문제를 해결하는 과정을 요구하기 때문에 학생들은 자연스럽게 문제를 작은 단위로 나누고 각 단계를 해결하는 방법을 생각하게 되고, 단계적인 논리적 사고와 문제 해결 능력을 키울 수 있습니다. 이는 학생들의 미래에도 큰 도움이 될 것입니다. 코딩 교육을 통해 학생들은 미래 직업에 대비하는 역량을 갖출 수 있습니다. 코딩을 배우고 익히는 과정에서 학생들은 IT 관련 직업에 대한 이해와 관심을 가질 수 있습니다.
프로그래밍 언어
초등학교 코딩 교육을 위한 우리의 준비
우리는 초등학교 코딩 교육을 더욱 더 중요하게 생각하고 학교와 교육 기관들 그리고 전문 지식을 갖춘 선생님들을 통해 코딩 교육을 강화하고 지원하는데 노력해야 합니다. 학생들이 코딩에 대한 흥미와 자신감을 가질 수 있도록 많은 전문가를 통해 제도와 지원이 마련되어야 합니다.
머신러닝 알고리즘은 데이터에서 패턴을 찾아내어 예측을 하거나 분류하는 등의 문제를 해결합니다. 지도학습은 레이블이 있는 데이터 셋을 통해 알고리즘으로 데이터를 구별하는 판별식을 만든 후 새로운 데이터가 어떠한 결과를 출력하는지 알아내는 학습 모델 입니다. 즉, 지도학습은 과거의 데이터를 학습해서 결과를 예측하는 방법 입니다.
‘지도학습’ 에 해당되는 세 가지 머신러닝 알고리즘 – KNN(K-Nearest Neighbors), 서포트 벡터 머신(Support Vector Machine), 의사결정 트리(Decision Tree) 에 대하여 간단한 파이썬 예제를 통해 머신러닝 알고리즘에 대해 연습해볼 수 있습니다.
pip install scikit-learn numpy
1. KNN(K-Nearest Neighbors)
KNN은 지연 학습(lazy learning) 방식에 속하는 알고리즘으로, 새로운 데이터 포인트를 분류할 때 학습 데이터셋 내에서 가장 가까운 K개의 이웃 데이터를 찾습니다. 이웃들의 다수결(voting) 혹은 평균 등을 사용해 예측 결과를 도출합니다.
장점: 구현이 간단하고, 직관적이며, 파라미터 조정이 비교적 쉽습니다.
단점: 데이터가 많아지면 계산 비용이 증가하고, 이상치(outlier)에 민감할 수 있습니다.
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
# 아이리스(iris) 데이터셋 로드
iris = load_iris()
X = iris.data
y = iris.target
# 데이터를 학습용과 테스트용으로 분할 (70%:30%)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# KNN 분류기 생성 (k=3)
knn = KNeighborsClassifier(n_neighbors=3)
knn.fit(X_train, y_train)
# 테스트 데이터로 예측 수행
y_pred = knn.predict(X_test)
print("KNN 정확도:", accuracy_score(y_test, y_pred))
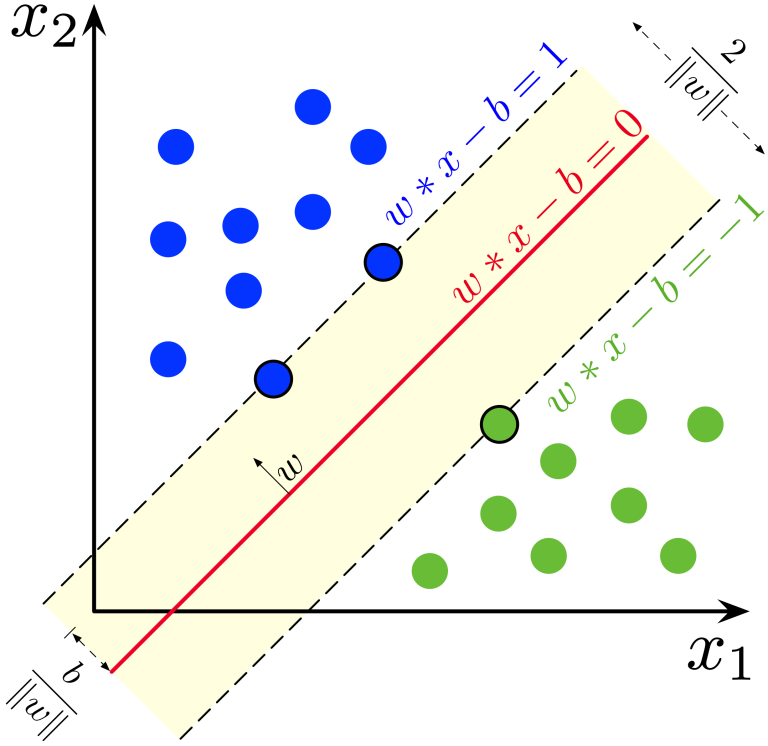
2. 서포트 벡터 머신 (SVM)
SVM은 데이터를 분리하는 최적의 결정 경계(hyperplane) 를 찾는 알고리즘입니다. 특히, 클래스 간의 마진(margin)을 최대화하는 결정 경계를 도출하여 분류 성능을 향상시킵니다.
장점: 고차원 데이터에서도 효과적이며, 커널 트릭(kernel trick)을 통해 비선형 문제도 해결할 수 있습니다.
단점: 데이터의 크기가 크거나 노이즈가 많을 경우 계산 비용이 증가할 수 있고, 파라미터 튜닝이 필요합니다.
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
# 아이리스 데이터셋 로드
iris = load_iris()
X = iris.data
y = iris.target
# 데이터를 학습용과 테스트용으로 분할 (70%:30%)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# SVM 분류기 생성 (선형 커널 사용)
svm = SVC(kernel='linear', random_state=42)
svm.fit(X_train, y_train)
# 테스트 데이터로 예측 수행
y_pred = svm.predict(X_test)
print("SVM 정확도:", accuracy_score(y_test, y_pred))
3. 의사결정 트리 (Decision Tree)
의사결정 트리는 데이터를 분할하는 기준(특성)을 순차적으로 선택하여, 트리 형태의 모델을 구성합니다. 각 노드에서 데이터를 특정 기준에 따라 분할함으로써, 최종적으로 각 리프 노드에서 클래스에 대한 예측을 수행합니다.
장점: 결과 해석이 용이하고, 시각화가 가능하여 모델 이해도가 높습니다.
단점: 과적합(overfitting)에 취약할 수 있으며, 작은 변화에도 모델 구조가 크게 달라질 수 있습니다.
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
# 아이리스 데이터셋 로드
iris = load_iris()
X = iris.data
y = iris.target
# 데이터를 학습용과 테스트용으로 분할 (70%:30%)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 의사결정 트리 분류기 생성
tree = DecisionTreeClassifier(random_state=42)
tree.fit(X_train, y_train)
# 테스트 데이터로 예측 수행
y_pred = tree.predict(X_test)
print("의사결정 트리 정확도:", accuracy_score(y_test, y_pred))
사실, 머신러닝은 더 깊게 들어가면 어려운 책 몇권 이상으로도 설명이 필요한 영역이지만 세 가지 모델 모두가 머신러닝을 이해하기 위한 기초적인 모델이기 때문에 간단하게 개념적으로 블로그에 올리게 되었습니다. 이론적인 배경 지식도 중요하지만, 각각의 알고리즘을 실제 데이터셋에 적용해보면서 실제로 코딩하면서 느끼는 경험을 하면 머신러닝에 좀더 쉽게 다가갈 수 있지 않을까요?
MNIST는 ‘Modified National Institute of Standards and Technology’의 약자로, 미국의 표준 기술 연구소에서 생성된 원래의 NIST 데이터셋을 수정하여 만들었습니다. 이 데이터셋은 손으로 쓴 숫자들의 이미지를 포함하고 있습니다. 이 데이터셋은 기계 학습 분야의 연구에 널리 사용되며, 특히 이미지 처리를 위한 벤치마크로 사용됩니다.
MNIST 데이터 셋
MNIST 데이터셋은 총 7만 개의 이미지로 구성되어 있습니다. 각 이미지는 28×28 픽셀로 이루어져 있고, 숫자 0부터 9까지를 손으로 쓴 글씨를 담고 있습니다. 이 중 6만 개는 훈련 데이터로, 1만 개는 테스트 데이터로 사용됩니다.
MNIST 데이터셋은 약 1990년대에 Yan LeCun, Corinna Cortes, 그리고 Christopher J.C. Burges에 의해 개발되었다고 합니다. 그들이 MNIST 데이터셋을 처음 만들었을 때, 그들의 주요 목표는 기계학습 알고리즘이 얼마나 잘 작동하는지 평가하고, 다양한 알고리즘 간에 성능을 비교하는 표준적인 벤치마크를 제공하는 것이 목적 이었으나 현재는 이 데이터셋을 생성함으로써, 머신러닝의 ‘비지도학습’ 에 해당하는 알고리즘(로지스틱 회귀, 서포트 벡터 머신, 신경망 등) 을 통해서 보다 큰 규모의 데이터셋의 성능 테스트와 훈련이 가능하게 되었습니다.
데이터셋의 크기와 다양성, 그리고 쉽게 접근할 수 있는 특징 덕분에, 우리가 보통 프로그램언어를 처음 배울때 개발하는 ‘Hello, World!’ 프로그램 처럼 MNIST는 머신러닝과 딥러닝 을 배우면서 처음 시도하는 프로그래밍 이라고 생각하면 될듯합니다.
MNIST 데이터셋은 비교적 간단한 구조를 가지고 있지만, 이미지 인식(캡챠, 사물 이미지 인식 등) 분야에서의 다양한 기법을 실험하고 평가하는 데 매우 유용합니다. Keras 라이브러리를 통해 아래 짧은 코드로 간단히 수행해 볼 수 있습니다.
수행 전 tensorflow 와 keras 가 설치가 되어있지 않으면 꼭 설치해야 합니다.
Iris 데이터셋은 통계학과 머신러닝에서 자주 사용되는 데이터셋 중 하나입니다. 이 데이터셋은 붓꽃(Iris)의 품종을 분류하기 위한 데이터셋으로, 총 세 가지 품종(Setosa, Versicolor, Virginica)의 정보가 각각 50개씩 총 150개의 샘플로 구성되어 있습니다.
Iris 데이터셋
출처 : Wikipedia
각 샘플은 아래와 같은 네 가지 특징을 가지고 있습니다.
꽃받침(sepal)의 길이
꽃받침의 너비
꽃잎(petal)의 길이
꽃잎의 너비
Iris 데이터셋의 각 샘플은 이 네 가지 특징에 대한 수치와 그에 해당하는 붓꽃의 품종으로 구성되어 있습니다. 이 데이터셋은 각 특징들 간의 관계를 분석하거나, 머신러닝 모델을 학습시키는데 주로 사용됩니다. Iris 데이터셋은 다양한 머신러닝 알고리즘과 유용한 도구가 포함된 Scikit-learn 라이브러리를 통해서 가져 올수 있습니다.
from sklearn import datasets
iris = datasets.load_iris()
위 코드를 실행하면, Iris 데이터셋이 ‘iris’라는 변수에 저장되게 됩니다. 이후 ‘iris.data’로 데이터를, ‘iris.target’으로 타겟값(붓꽃의 품종)을 확인할 수 있습니다. pip 나 conda 명령어중 한가지 명령어를 통해 Scikit-learn을 설치할 수 있습니다.
pip 명령어 사용시
pip install scikit-learn
Conda 명령어 사용시
conda install scikit–learn
만약 설치 오류가 발생하거나 이미 ScyPi, Numpy 가 설치 되어 있다면 다음 명령어로 수행 합니다.
conda install -c conda-forge scikit-learn
참고로, Scikit-learn이 이미 설치되어 있다면, 별도로 Iris 데이터셋을 다운로드 받을 필요는 없습니다. 정상으로 설치가 되었다면 다음 소스를 통해 예제가 출력되는지 확인 해 봅니다.
from sklearn import datasets
# Iris 데이터셋 로드
iris = datasets.load_iris()
# 데이터셋에서 처음 5개의 샘플을 출력
print(“First 5 samples:”)
print(iris.data[:5])
# 해당 샘플들의 타겟값(붓꽃의 품종) 출력
print(“\nTarget of the samples:”)
print(iris.target[:5])
node.js 는 오픈소스로서 첫 탄생은 2009년 5월 27일 처음 소개되었고 Ryan Dahl 개발자에 의해서 웹 브라우저에서 동작하는 JavaScript 엔진인 V8을 구글이 개발했던 걸 보고 영감을 받았다고 합니다. 그리고 “이것을 서버에서도 사용할 수 있을까?”라는 생각이 들었고 V8 엔진을 이용하여 JavaScript 코드를 서버에서 실행할 수 있도록 개발하기 시작했습니다. 이렇게 탄생한 것이 바로 “노드(Node.js)” 입니다. 이렇게 해서, 개발자들은 웹 브라우저에서만 사용하던 JavaScript를 이제 서버에서도 사용할 수 있게 되었습니다.
node.js는 JavaScript 런타임 환경으로, 웹 애플리케이션 개발에 매우 유용한 도구입니다. node.js는 가장 큰 특징은 비동기 처리 방식입니다. Ryan은 이 비동기 처리를 위해 이벤트 루프(event loop)와 콜백(callback) 함수를 도입했습니다. 다양한 동시 연결과 트랜젝션을 효율적으로 처리할 수 있게 되었고 놀라울 정도로 빠른 속도와 안정성 대중화로 PayPal, Netflix, Uber, LinkedIn 등 세계적으로 유명한 기업들이 node.js 를 활용하여 서비스를 제공하고 있습니다.
Ryan과 더 많은 개발자들이 더 쉽게 모듈과 라이브러리를 공유하기 위해 npm(node package manager)을 만들게 되었습니다. 이 패키지 매니저를 통해 개발자들은 수많은 모듈과 라이브러리를 손쉽게 설치하고 관리할 수 있게 되었고 의존성 관리, 종속성, 버전관리 등 다양한 패키지를 설치하고 관리할 수 있습니다.
이제 node.js를 사용하여 웹 애플리케이션을 개발하는 방법에 대하여 다음과 같이 npm 명령어를 통해 설치하는 방법 과 실제 서버를 띄우는 것 까지 연습해 보겠습니다.
1. node.js와 rpm 설치하기
첫 단계는 node.js와 npm 을 설치하는 것입니다. node.js 공식 웹사이트에서 다운로드하여 설치합니다. 설치가 완료되면 터미널 또는 명령 프롬프트에서 node -v과 npm -v 명령어로 설치 여부를 확인합니다.
2. 프로젝트 생성과 초기화
새로운 프로젝트 폴더를 생성하고, 터미널에서 해당 폴더로 이동합니다. 다음 명령어를 실행하여 프로젝트를 초기화합니다:
npm init
프로젝트에 대한 정보를 입력하면 package.json 파일이 생성됩니다.
3. express.js 프레임워크 설치
express.js는 node.js 를 사용하기 위한 웹 프레임워크 입니다. 다음 명령어를 사용하여 express.js를 설치 합니다.
npm install express
4. 간단한 웹 서버 구축 하기
새로운 파일 app.js를 생성하고 다음과 같은 코드를 입력합니다:
const express = require('express');
const app = express();
const port = 3000;
app.get('/', (req, res) => {
res.send('Hello, World!');
});
app.listen(port, () => {
console.log(`서버가 http://localhost:${port} 에서 실행 중입니다.`);
});
LSTM(Long Short-Term Memory)은 순환 신경망(Recurrent Neural Network, RNN)의 한 종류로서, 시퀀스 데이터 (시계열 데이터, 텍스트 등)를 처리하기 위해 신경망 입니다. 이전에 배운 것들을 기억할 수 있도록 컴퓨터 의 “일기장” 을 바로 LSTM 이라고 할 수 있습니다. 즉, “일기장”을 찾아보면서 이전에 무슨 일이 있었는지 확인을 할 수 있으며 미래에 무슨 일이 일어날지 예측을 할 수 있습니다.
예를 들어, 작곡을 할 때, LSTM은 이전에 어떤 음이 나왔었는지 기억하고, 그 다음에 어떤 음이 나와야 할지 도와줍니다. 현재도 실제로 아티스트들은 이미 Ai를 통해 작곡을 하고 수 있습니다.
RNN(순환 신경망)은 이전 시점의 출력을 현재 시점의 입력에 포함시켜 정보를 순환시키는 구조를 가지고 있습니다. 하지만, 시퀀스가 길어질수록 이전 시점의 정보가 잘 전달되지 않는 ‘장기 의존성 문제’ 를 해결하기 위해 ‘셀 상태’라는 개념을 도입했습니다. 셀 상태는 LSTM 셀을 통과하는 동안 정보를 전달하는 ‘Information Highway’와 같습니다. LSTM에서는 게이트라는 구조를 통해 셀 상태에 어떤 정보를 추가하거나 제거할지 결정합니다. 이로 인해 LSTM은 긴 시퀀스에서도 이전 정보를 잘 기억하고 전달할 수 있습니다.
이 이미지는 LSTM “셀”의 내부 구조를 보여줍니다. 각각의 작은 박스는 다른 역할을 하는 “게이트”를 나타내고, 화살표는 정보가 어떻게 이동하는지를 보여줍니다. 이 중 가장 중요한 부분은 가장 위에 있는 수평선인 ‘셀 상태’입니다. 바로 “일기장”과 같은 역할을 하며 이를 통해 LSTM은 장기적인 정보를 저장하고 전달할 수 있습니다.
LSTM 활용사례
1. 자연어 처리(Natural Language Processing, NLP): LSTM은 텍스트 데이터에서 잘 작동하므로, 감성 분석, 텍스트 생성, 기계 번역 등 다양한 NLP 작업에 활용될 수 있습니다.
2. 시계열 예측(Time Series Prediction): LSTM은 시간에 따른 패턴을 학습할 수 있으므로, 주식 가격 예측, 날씨 예측 등 시계열 데이터의 예측에 사용될 수 있습니다.
3. 음성 인식(Speech Recognition): LSTM은 시간에 따라 변화하는 음성 신호를 처리하는 데 유용하므로, 음성 인식 기술에도 사용됩니다.
4. 음악 생성(Music Generation): LSTM은 시퀀스 데이터를 생성하는 데에도 사용될 수 있습니다. 이러한 특성을 이용해 음표의 시퀀스를 학습하고 새로운 음악을 생성하는 데에 사용될 수 있습니다.
Conda와 Pip는 파이썬 프로그래밍을 위해 패키지를 관리하는 데 설치 되는 도구입니다. 프로젝트나 개발을 위해 모두 개발을 위해 사용하지만 그 사용 방식과 장점은 다릅니다. Conda와 Pip의 차이점과 각각의 사용 방법을 살펴보고자 합니다.
Conda 란?
anaconda
Conda : Anaconda(Anaconda: 아마존의 아나콘다 뱀에서 이름을 따왔다고 함) 클라우드 저장소와 Continuum 소프트웨어 사의 패키지 저장소에서 패키지를 관리합니다. Conda의 장점은 바로 의존성을 자동으로 해결해주는 강력한 의존성 관리 기능을 그리고 Anaconda를 통해 가상환경을 제공합니다
특히 TensorFlow를 설치할 때 다양한 패키지와 라이브러리에 의존하며, 이러한 의존성을 수동으로 설치를 해야하는 단점을 한방에 해결해줍니다.
Conda의 가장 큰 장점은 바로 의존성 관리입니다. Conda는 패키지와 라이브러리의 의존성을 자동으로 해결해주며, 이를 통해 패키지 설치 시 충돌이나 버전 불일치 문제를 최소화합니다. 또한, Conda는 가상 환경 관리 기능을 제공하여, 여러 프로젝트별로 독립적인 환경을 생성하고 관리할 수 있게 해줍니다. 이로 인해, 각 프로젝트에서 사용하는 라이브러리의 버전이나 의존성이 다른 경우에도 문제가 발생하지 않도록 할 수 있습니다. Anaconda는 데이터 과학, 머신러닝, 인공지능 관련 패키지들이 기본으로 포함되어 있어, 복잡한 설정 없이 바로 작업을 시작할 수 있다는 장점도 가지고 있습니다.
Pip 란?
python
Pip : Pip Installs Packages 또는 Pip Installs Python 라고 정의. PyPI (Python Package Index) 저장소에서 패키지를 관리합니다. Pip는 파이썬 전용 패키지 관리 도구로, 주로 파이썬 언어로 작성된 라이브러리나 모듈을 설치하고 관리하는 데 사용됩니다.
Pip는 PyPI에서 제공하는 수많은 오픈 소스 파이썬 패키지를 쉽게 설치할 수 있게 도와주며, 프로젝트마다 독립적인 환경을 관리할 수 있는 가상 환경 관리 도구인 virtualenv나 venv와 함께 사용할 수 있습니다. Pip의 가장 큰 특징은 단순한 사용법과 빠른 설치입니다. pip install 명령어로 원하는 패키지를 손쉽게 설치할 수 있으며, 설치 시 의존성 해결도 자동으로 이루어집니다. 하지만 Conda와 달리 파이썬 외의 다른 언어에 대한 의존성 관리나 가상 환경의 관리 기능을 제공하지 않으며, 모든 패키지가 PyPI에 올라와야만 설치가 가능합니다. 또한, 의존성 충돌이 발생할 수 있어 더 복잡한 환경에서 사용 시 주의가 필요합니다.
Conda 와 Pip 비교
특성
Conda
pip
정의
크로스 플랫폼, 언어-중립적 패키지 관리자와 환경 관리 시스템
파이썬으로 작성된 패키지들을 설치하고 관리하는 도구
지원 언어
파이썬 패키지 뿐만 아니라 R, Ruby, Lua, Scala, Java, JavaScript, C/C++, FORTRAN 등 다양한 언어의 패키지를 관리할 수 있음
아나콘다(Anaconda)는 데이터 과학, 머신러닝, 딥러닝 등의 과학 계산 작업을 쉽게 수행할 수 있는 배포판이다. 아나콘다는 패키지 관리자로서의 역할을 하며, 파이썬과 여러 종류 라이브러리를 쉽게 설치하고 관리할 수 있는 환경을 제공하는 것이 장점이다.
아나콘다의 핵심 기능 중 하나는 ‘환경(Environment)’ 을 생성하고 관리하는 것. 환경은 특정한 프로젝트를 위해 필요한 파이썬 버전과 패키지를 독립적으로 관리할 수 있고, 이를 통해 여러 프로젝트가 서로 다른 라이브러리나 파이썬 버전을 요구할 경우에도 각각의 프로젝트에 맞는 환경 관리할 수 있다.