LSTM(Long Short-Term Memory)은 순환 신경망(Recurrent Neural Network, RNN)의 한 종류로서, 시퀀스 데이터 (시계열 데이터, 텍스트 등)를 처리하기 위해 신경망 입니다. 이전에 배운 것들을 기억할 수 있도록 컴퓨터 의 “일기장” 을 바로 LSTM 이라고 할 수 있습니다. 즉, “일기장”을 찾아보면서 이전에 무슨 일이 있었는지 확인을 할 수 있으며 미래에 무슨 일이 일어날지 예측을 할 수 있습니다.
예를 들어, 작곡을 할 때, LSTM은 이전에 어떤 음이 나왔었는지 기억하고, 그 다음에 어떤 음이 나와야 할지 도와줍니다. 현재도 실제로 아티스트들은 이미 Ai를 통해 작곡을 하고 수 있습니다.
RNN(순환 신경망)은 이전 시점의 출력을 현재 시점의 입력에 포함시켜 정보를 순환시키는 구조를 가지고 있습니다. 하지만, 시퀀스가 길어질수록 이전 시점의 정보가 잘 전달되지 않는 ‘장기 의존성 문제’ 를 해결하기 위해 ‘셀 상태’라는 개념을 도입했습니다. 셀 상태는 LSTM 셀을 통과하는 동안 정보를 전달하는 ‘Information Highway’와 같습니다. LSTM에서는 게이트라는 구조를 통해 셀 상태에 어떤 정보를 추가하거나 제거할지 결정합니다. 이로 인해 LSTM은 긴 시퀀스에서도 이전 정보를 잘 기억하고 전달할 수 있습니다.
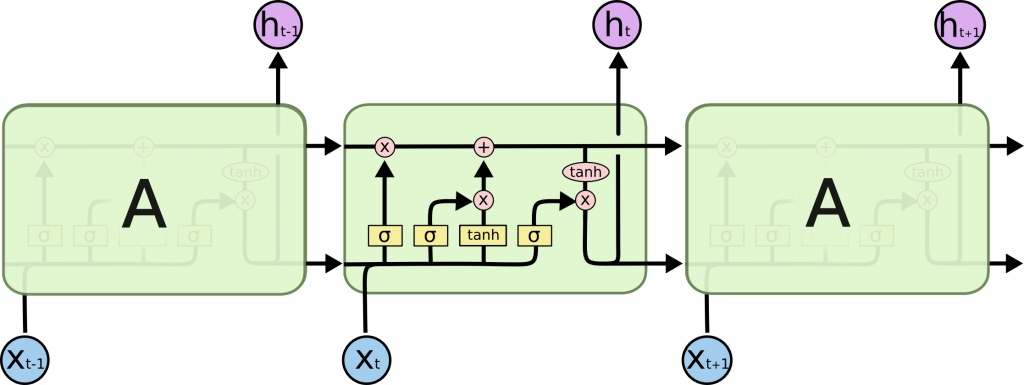
이 이미지는 LSTM “셀”의 내부 구조를 보여줍니다. 각각의 작은 박스는 다른 역할을 하는 “게이트”를 나타내고, 화살표는 정보가 어떻게 이동하는지를 보여줍니다. 이 중 가장 중요한 부분은 가장 위에 있는 수평선인 ‘셀 상태’입니다. 바로 “일기장”과 같은 역할을 하며 이를 통해 LSTM은 장기적인 정보를 저장하고 전달할 수 있습니다.
LSTM 활용 사례 : 자연어 처리(Natural Language Processing, NLP)
LSTM(Long Short-Term Memory)은 자연어 처리(NLP) 분야에서 탁월한 성능을 발휘하는 순환 신경망(RNN)의 한 종류입니다. 텍스트 데이터의 시간적 흐름과 문맥을 효과적으로 처리하여 다양한 NLP 작업에 활용되고 있습니다.
자연어처리(NLP)는 우리가 사용하는 자연어를 컴퓨터가 이해하고 처리할 수 있도록 돕는 기술입니다. 예를 들어, 우리가 “장보기 목록에 계란과 우유 추가”라고 말할 때, 인간은 이 말을 쉽게 이해하지만, 컴퓨터는 이를 처리하기 어려운 비구조적인 텍스트로 간주합니다. NLP는 이러한 비구조적인 텍스트를 컴퓨터가 이해할 수 있는 구조화된 형태로 변환합니다.
*참고: IBM Technology 영상 : 내용정리가 상당한 수준이라 강추!!
NLP는 크게 두 가지 중요한 과정, 즉 자연어 이해(NLU)와 자연어 생성(NLG)으로 나뉩니다. NLU는 비구조적 데이터를 구조적으로 변환하는 과정이며, NLG는 구조적 데이터를 다시 비구조적 데이터로 변환하는 과정입니다.
NLP의 주요 활용 사례
- 기계 번역: NLP는 문장 전체의 맥락을 이해하여 정확한 번역을 제공합니다. 예를 들어, “정신은 의지가 있지만, 육체는 약하다”라는 문장을 번역할 때, 단어 단위 번역이 아닌 문맥을 고려하여 번역이 필요합니다.
- 가상 비서 및 챗봇: Siri나 Alexa와 같은 가상 비서는 사용자의 음성 명령을 이해하고 실행합니다. 또한, 챗봇은 사용자의 글을 이해하고 이에 맞는 답변을 제공합니다.
- 감정 분석: 이메일이나 제품 리뷰를 분석하여 긍정적인 감정인지, 부정적인 감정인지, 심지어는 비꼬는 표현이 포함된 것인지 판단합니다.
- 스팸 감지: 이메일 메시지에서 스팸을 판별하는 데에도 NLP가 활용됩니다. 과도하게 사용된 단어, 부적절한 문법, 긴급함을 강조하는 표현 등을 통해 스팸 여부를 판단할 수 있습니다.
NLP의 동작 원리
NLP(자연어처리)는 하나의 알고리즘만 사용하는 것이 아니라, 여러 도구들을 조합해서 다양한 문제를 해결합니다. NLP가 작동하는 과정을 쉽게 설명하면 다음과 같습니다.
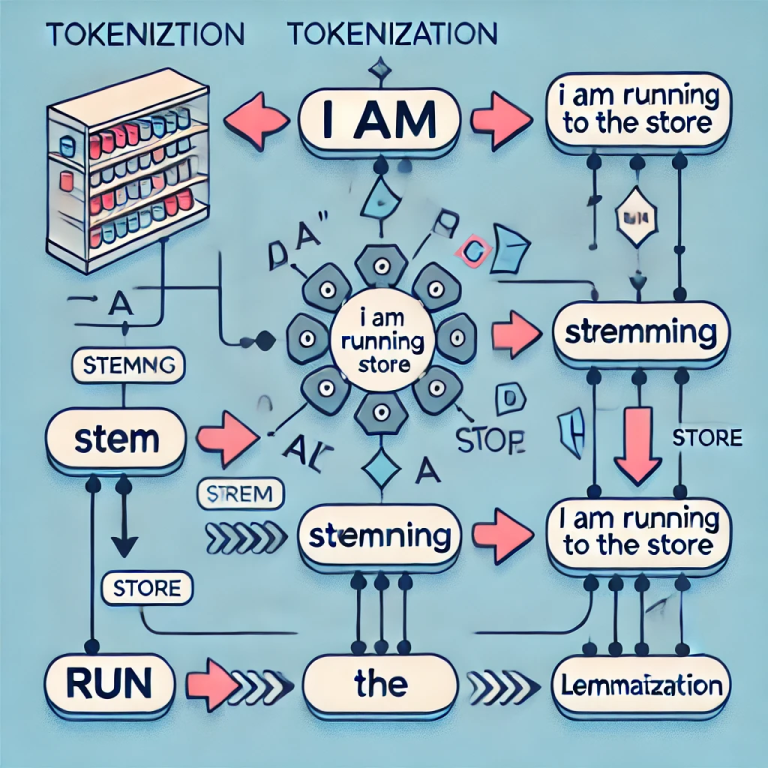
먼저, 컴퓨터가 처리할 텍스트는 비구조적 텍스트입니다. 예를 들어, 사람이 쓰는 일상적인 문장들이 바로 비구조적 텍스트죠. 이 텍스트는 컴퓨터가 바로 이해하기 어려운 형태이기 때문에, 먼저 **토큰화(tokenization)**라는 과정을 거쳐서 텍스트를 작은 단위로 나눕니다. 예를 들어, “오늘 날씨는 맑아요”라는 문장이 있으면, 이 문장은 “오늘”, “날씨는”, “맑아요”처럼 작은 단어로 나눠집니다.
이후, 각 단어의 어근 추출(stemming) 또는 **표제어 추출(lemmatization)**을 통해 단어의 기본 형태를 찾습니다. 예를 들어, “달리다”, “달린다”, “달리고”와 같은 단어들이 있을 때, 이들을 “달리다”라는 기본형으로 바꾸는 작업이 이루어집니다.
그 다음에는 각 단어가 문장에서 어떤 역할을 하는지 판단하는 **품사 태깅(part-of-speech tagging)**을 합니다. 예를 들어, “밥을 먹다”라는 문장에서 “밥”은 명사이고 “먹다”는 동사라는 것을 구분하는 과정입니다.
또한, **명명된 엔티티 인식(NER)**을 통해 텍스트 속에 중요한 정보가 있는지 확인합니다. 예를 들어, “서울에 있는 경복궁은 유명한 관광지입니다”라는 문장에서 “서울”은 장소, “경복궁”은 특정 명사(관광지의 이름)로 인식됩니다.
이 모든 과정을 거친 후, NLP는 인간이 사용하는 언어를 컴퓨터가 이해할 수 있는 구조적 데이터로 변환합니다. 이 구조적 데이터는 이후 다양한 AI 응용 프로그램에서 활용될 수 있습니다.