머신러닝 알고리즘은 데이터에서 패턴을 찾아내어 예측을 하거나 분류하는 등의 문제를 해결합니다. 지도학습은 레이블이 있는 데이터 셋을 통해 알고리즘으로 데이터를 구별하는 판별식을 만든 후 새로운 데이터가 어떠한 결과를 출력하는지 알아내는 학습 모델 입니다. 즉, 지도학습은 과거의 데이터를 학습해서 결과를 예측하는 방법 입니다.
‘지도학습’ 에 해당되는 세 가지 머신러닝 알고리즘 – KNN(K-Nearest Neighbors), 서포트 벡터 머신(Support Vector Machine), 의사결정 트리(Decision Tree) 에 대하여 간단한 파이썬 예제를 통해 머신러닝 알고리즘에 대해 연습해볼 수 있습니다.
pip install scikit-learn numpy
1. KNN(K-Nearest Neighbors)
KNN은 지연 학습(lazy learning) 방식에 속하는 알고리즘으로, 새로운 데이터 포인트를 분류할 때 학습 데이터셋 내에서 가장 가까운 K개의 이웃 데이터를 찾습니다. 이웃들의 다수결(voting) 혹은 평균 등을 사용해 예측 결과를 도출합니다.
- 장점: 구현이 간단하고, 직관적이며, 파라미터 조정이 비교적 쉽습니다.
- 단점: 데이터가 많아지면 계산 비용이 증가하고, 이상치(outlier)에 민감할 수 있습니다.

from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
# 아이리스(iris) 데이터셋 로드
iris = load_iris()
X = iris.data
y = iris.target
# 데이터를 학습용과 테스트용으로 분할 (70%:30%)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# KNN 분류기 생성 (k=3)
knn = KNeighborsClassifier(n_neighbors=3)
knn.fit(X_train, y_train)
# 테스트 데이터로 예측 수행
y_pred = knn.predict(X_test)
print("KNN 정확도:", accuracy_score(y_test, y_pred))2. 서포트 벡터 머신 (SVM)
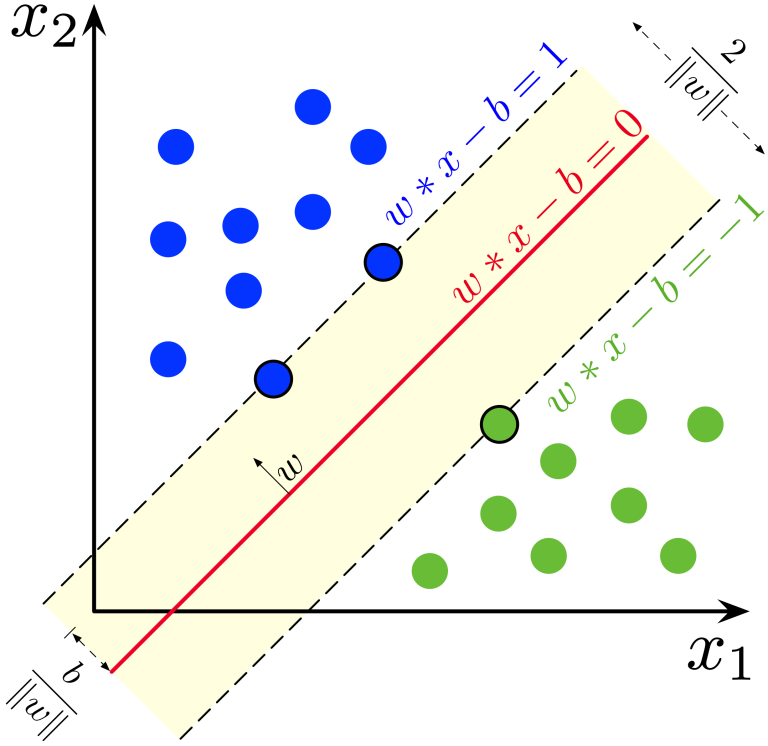
SVM은 데이터를 분리하는 최적의 결정 경계(hyperplane) 를 찾는 알고리즘입니다. 특히, 클래스 간의 마진(margin)을 최대화하는 결정 경계를 도출하여 분류 성능을 향상시킵니다.
- 장점: 고차원 데이터에서도 효과적이며, 커널 트릭(kernel trick)을 통해 비선형 문제도 해결할 수 있습니다.
- 단점: 데이터의 크기가 크거나 노이즈가 많을 경우 계산 비용이 증가할 수 있고, 파라미터 튜닝이 필요합니다.
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
# 아이리스 데이터셋 로드
iris = load_iris()
X = iris.data
y = iris.target
# 데이터를 학습용과 테스트용으로 분할 (70%:30%)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# SVM 분류기 생성 (선형 커널 사용)
svm = SVC(kernel='linear', random_state=42)
svm.fit(X_train, y_train)
# 테스트 데이터로 예측 수행
y_pred = svm.predict(X_test)
print("SVM 정확도:", accuracy_score(y_test, y_pred))3. 의사결정 트리 (Decision Tree)
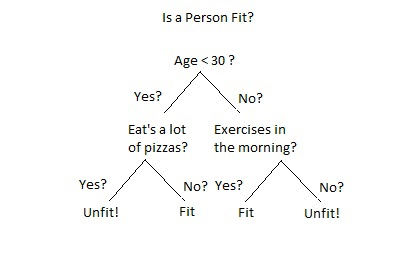
의사결정 트리는 데이터를 분할하는 기준(특성)을 순차적으로 선택하여, 트리 형태의 모델을 구성합니다. 각 노드에서 데이터를 특정 기준에 따라 분할함으로써, 최종적으로 각 리프 노드에서 클래스에 대한 예측을 수행합니다.
- 장점: 결과 해석이 용이하고, 시각화가 가능하여 모델 이해도가 높습니다.
- 단점: 과적합(overfitting)에 취약할 수 있으며, 작은 변화에도 모델 구조가 크게 달라질 수 있습니다.
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
# 아이리스 데이터셋 로드
iris = load_iris()
X = iris.data
y = iris.target
# 데이터를 학습용과 테스트용으로 분할 (70%:30%)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 의사결정 트리 분류기 생성
tree = DecisionTreeClassifier(random_state=42)
tree.fit(X_train, y_train)
# 테스트 데이터로 예측 수행
y_pred = tree.predict(X_test)
print("의사결정 트리 정확도:", accuracy_score(y_test, y_pred))
사실, 머신러닝은 더 깊게 들어가면 어려운 책 몇권 이상으로도 설명이 필요한 영역이지만 세 가지 모델 모두가 머신러닝을 이해하기 위한 기초적인 모델이기 때문에 간단하게 개념적으로 블로그에 올리게 되었습니다. 이론적인 배경 지식도 중요하지만, 각각의 알고리즘을 실제 데이터셋에 적용해보면서 실제로 코딩하면서 느끼는 경험을 하면 머신러닝에 좀더 쉽게 다가갈 수 있지 않을까요?